
深入理解 Git 底层实现原理

一直以来,关于 Git 的底层原理其实是一知半解的。直到最近,在理解了文件系统的设计原理,并阅读了 Linus Torvalds 的第一版 Git 源码之后,终于彻底搞明白了 Git 的设计哲学。
借此机会,总结一下自己对于 Git 底层原理的理解。当然,关于 Git 的学习,《Pro Git》仍然是最权威的参考书籍。本文只不过是在此基础上,梳理了一下笔者自己的理解,希望能够达到深入浅出的效果。
注:Git 本质上是一个内容寻址的文件系统,如果你希望有一个更加深入的理解,建议先阅读 《深入理解 Linux Ext 文件系统设计原理》。
起源
从 Linux 诞生以来,它就有着为数众多的参与者,在很长一段时间里,绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年期间)。直到 2002 年,整个开源项目组开始启用一个专有的分布式版本控制系统 BitKeeper 来管理和维护代码。
2005 年,一位社区开发者反编译 BitKeeper 并利用了其未公开的接口,导致 BitKeeper 回收了 Linux 内核社区关于 BitKeeper 的使用许可。对此,Linus Torvalds 利用假期时间开发了一款全新的分布式版本控制工具——Git。
整体架构
下图所示为 Git 的整体架构示意图,其主要包含三大部分:
- 上层命令(Porcelain Commands)
- 底层命令(Plumbing Commands)
- 对象数据库(Object Database)
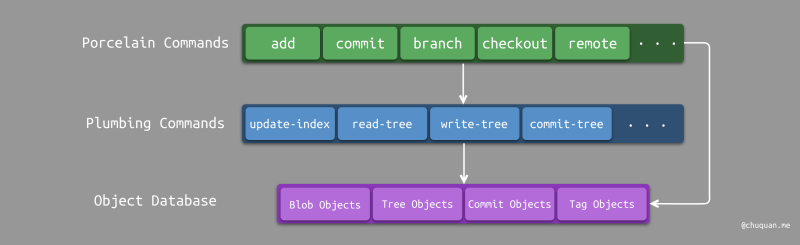
上层命令
在日常开发中,我们所使用的
Git命令基本上都是上层命令,如:commit、add、checkout、branch、remote
等。上层命令通过组合底层命令或直接操作底层数据对象,使 Git
底层实现细节对用户透明,从而为用户提供了一系列简单易用的命令集合。
底层命令
在日常开发中,我们基本接触不到 Git
的底层命令,如果要想使用这些底层命令,我们必须要对 Git
的设计原理有一定的认知。Linus Torvalds 的第一版
Git,其实就是实现了几个核心的底层命令,如:update-cache、write-tree、read-tree、commit-tree、cat-file、show-diff
等。注意,在底层命令的命名上,我们当前版本与最初版本存在细微的差异,下表是几个核心底层命令的简单对照。
| 当前版本 | 原始版本 |
|---|---|
git update-index |
update-cache |
git write-tree |
write-tree |
git read-tree |
read-tree |
git commit-tree |
commit-tree |
git cat-file |
cat-file |
对象数据库
Git 最核心、最底层 的部分则是其所实现的一套 对象数据库(Object Database),其本质是一个基于 Key-Value 的内容寻址文件系统(Content-addressable File System)。笔者认为其设计理念与传统的文件系统的设计理念极其相似,为了方便理解和对照,因此在下文中,我们将以 Git 文件系统 作为简称。
Git 文件系统中存储了所有文件的所有历史快照,通过索引不同的历史快照,Git 才能够实现版本控制。下面,我们来介绍一下 Git 文件系统。
Git 文件系统 vs Ext 文件系统
为了便于理解,我们使用 Linux Ext 文件系统与 Git 文件系统进行对比。
存储方式
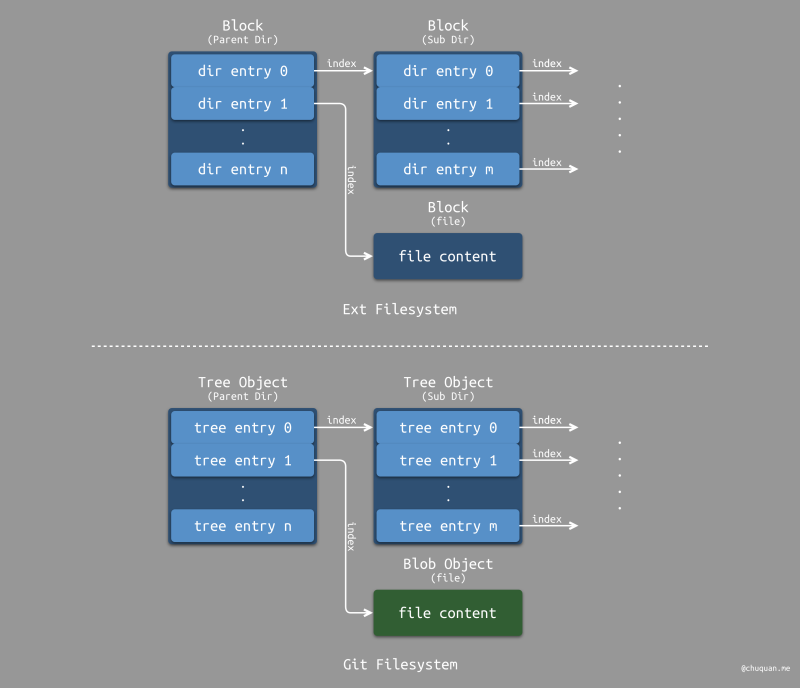
在 Ext 文件系统中,使用 Block 存储所有类型的内容;在 Git 文件系统中,使用 Object 存储所有类型的内容,也称为 Git 对象,不同类型的 Object 共同构成了一整套对象模型。
对于普通类型文件,Ext 文件系统 使用一个或多个 Block 存储文件内容;Git 文件系统 使用一个 Blob Object(二进制对象)存储文件内容。
对于目录类型文件,Ext 文件系统 使用一个 Block 存储一系列目录项(dir entry),每个目录项存储一个普通文件或目录文件的元数据;Git 文件系统 使用一个 Tree Object(树对象)存储一系列树对象记录(tree entry),每个树对象记录存储一个 Blob Object(对应一个普通文件)或一个 Tree Object(对应一个目录文件)的元数据。
下图所示,为两种文件系统关于目录和文件的组织方式的对比示意图。
索引方式
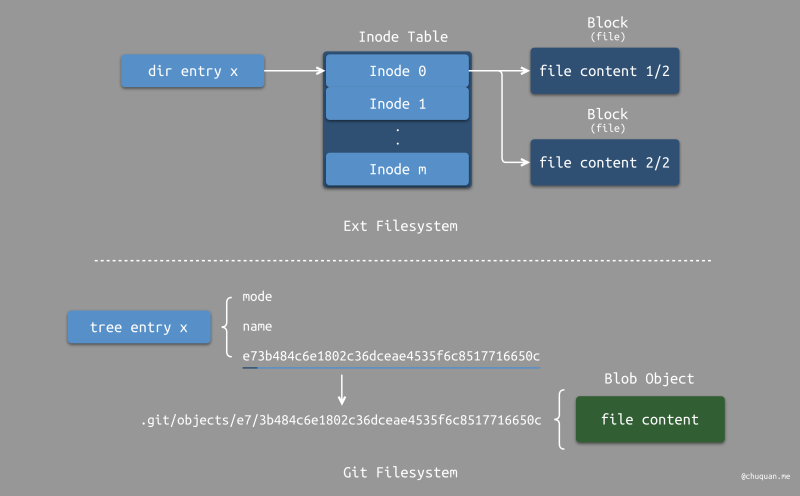
上图中,我们使用 “index” 简单地表示了文件的索引过程。事实上,文件系统的索引方式也是经过特殊设计的。
在 Ext 文件系统中,使用一个 Inode
记录一个文件或目录存储内容时占用的所有 Block
的序号,最终通过硬盘控制器进行索引;在 Git
文件系统中,使用一个 40 位的 SHA-1
值作为一个文件或目录存储内容时所占用的一个 Object
文件的唯一标识符,最终在 .git/objects/
目录下进行匹配查找,其中前 2 位 SHA-1 值作为存储子目录,后 38 位 SHA-1
值作为文件名。
对象模型
通过对比 Git 文件系统和 Ext 文件系统,我们基本了解了 Git 是如何存储和索引文件及目录的。接下来,我们来深入了解 Git 的对象模型,即数据存储的基本单元及类型。
Git 对象模型主要包括以下 4 种对象
- 二进制对象(Blob Object)
- 树对象(Tree Object)
- 提交对象(Commit Object)
- 标签对象(Tag Object)
所有对象均存储在 .git/objects/
目录下,并采用相同格式进行表示,其可以分为两部分:
- 头部信息:类型 + 空格 + 内容字节数 + \0
- 存储内容
Git 使用两部分内容的 40 位 SHA-1 值(前 2 为作为子目录,后 38 位作为文件名)作为快照文件的唯一标识,并对它们进行 zlib 压缩,然后将压缩后的结果作为快照文件的实际内容进行存储。
下面,我们来主要介绍一下其中前三种对象类型。
Blob Object
Block Object 用于存储普通文件的内容数据,其头部信息为 "blob" + 空格 + 内容字节数 + \0,存储内容为对应文件的内容快照。
下面,我们使用底层命令 git cat-file 来查看 analyze-git
仓库的一个 Blob Object 的存储内容。
1 | # 查看对象的类型 |
Tree Object
Tree Object 用于存储目录文件的内容数据,其头部信息为 "tree" + 空格 + 内容字节数 + \0,存储内容为 一个或多个树对象记录(Tree Entry)。
其中,树对象记录的结构(Git v2.0.0)为:文件模式 + 空格 + 树对象记录的字节数 + 文件路径 + \0 + SHA-1。
如果某一时刻,Git 仓库的文件结构如下所示,那么在 Git
文件系统中,会建立一个对象关系图,如下图所示。 1
2
3
4
5
6$ tree
.
├── bak
│ └── test.txt
├── new.txt
└── test.txt
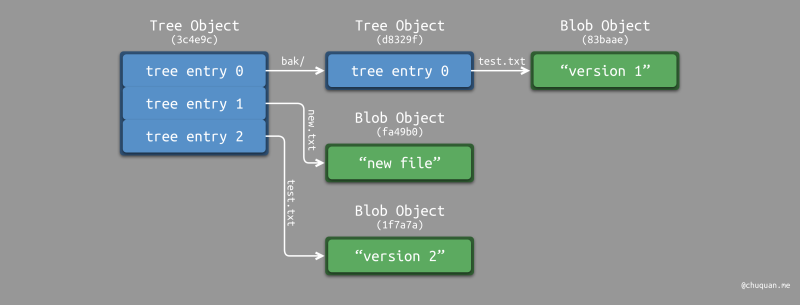
注意,当我们执行 git add(进入暂存区)时,Git
会为暂存文件创建 Blob Object,为暂存目录创建 Tree Object
,结合未修改文件和目录的
Object,建立一个整体的索引关系,从而形成一个版本快照。
Commit Object
Tree Object 和 Blob Object 用于表示版本快照,Commit Object 则不同,它 用于表示版本索引和版本关系。
此外,Tree Object 和 Blob Object 的 SHA-1 值是根据内容计算得到的,只要内容相同,SHA-1 值相同;而 Commit Object 会结合内容、时间、作者等数据,因此 SHA-1 值很难出现冲突。
Commit Object 的头部信息为 "commit" + 空格 + 内容字节数 + \0,存储内容包含多个部分(Git v2.0.0),具体如下图所示。
- 对应的根 Tree Object 对应的 SHA-1
- 一个或多个父级 Commit Object 对应的 SHA-1。当进行分支合并时就会出现多个父级 Commit Object。
- 提交相关内容,包括:作者信息、提交者信息、编码、提交描述等

下图所示,为 Commit Object 与 Tree Object 的关系示意图。每一个 Commit Object 索引一个版本快照,每一个版本快照则是由一个 Tree Object 作为根节点进行构建。不同的版本快照之间会进行数据复用,从而最大限度地节省磁盘空间。每一个 Commit Object 记录了其父版本的索引信息,即另一个 Commit Object 的 SHA-1 值,从而构建了一个完整的版本关系图(有向无环图)。通过版本关系图,我们可以基于一个 Commit Object 回溯其任意历史版本。

引用
如果我们对仓库的某一个提交及其历史版本感兴趣,那么我们可以使用该提交的 SHA-1 值进行查找。显然,直接使用 SHA-1 值来记忆是非常不便且易错的。对此,Git 提供了容易记忆的 “别名” 来代替 SHA-1 值,这就是 “引用(referrences,简称 refs)”。
Git 支持三种引用类型,不同的引用类型对应的引用文件各自存储在
.git/refs/ 下的不同子目录中。
- HEAD 引用
- 标签引用
- 远程引用
HEAD 引用
当我们执行 git branch <branch> 新建一个分支时,Git
是如何知道最新提交的 SHA-1 值呢?答案就是 HEAD
文件。
HEAD 文件通常是一个 符号引用(symbolic reference),指向当前所在的分支。所谓符号引用,表示它是一个指向其他引用的指针,类似于符号链接。
在某些特殊情况下,HEAD 文件可能会包含一个 Git 对象的 SHA-1 值。当我们在检出一个标签、提交或远程分支时,让仓库变成 “分离 HEAD” 状态时,就会出现这种情况。
我们可以通过 analyze-git 来查看
HEAD 文件。 1
2
3
4
5
6
7$ git checkout master
$ cat .git/HEAD
ref: refs/heads/master
$ git checkout test
$ cat .git/HEAD
ref: refs/heads/test
当我们执行 git commit 时,该命令会使用 HEAD
文件中引用所指向的 SHA-1 值作为其父提交,创建一个 Commit Object。
标签引用
标签引用(Tag Reference)包含两种类型:轻量标签 和 附注标签。
轻量标签
对于轻量标签,我们可以通过如下命令进行创建。 1
2
3$ git update-ref refs/tags/v1.0 a9f2652cb992f300c0a251d3607bdabfe8901bb2
$ cat .git/refs/tags/v1.0
a9f2652cb992f300c0a251d3607bdabfe8901bb2
该命令会创建一个以标签名命名的文本文件,文件内容为其所引用的 Commit Object 的 SHA-1 值。
附注标签
对于附注标签,我们可以通过如下命令进行创建。 1
$ git tag -a v1.1 e73b484c6e1802c36dceae4535f6c85 -m "test tag"
该命令会创建一个 标签对象(Tag Object),存储在
.git/objects/ 目录下。
Tag Object 是第 4 种 Git 对象,其头部信息为 "tag" + 空格 + 内容字节数 + \0,存储内容包含多个部分(Git v2.0.0),具体如下图所示。
- 所引用对象的 SHA-1 值
- 所引用对象的类型
- 标签名称
- 标签创建者和日期
- 注释信息
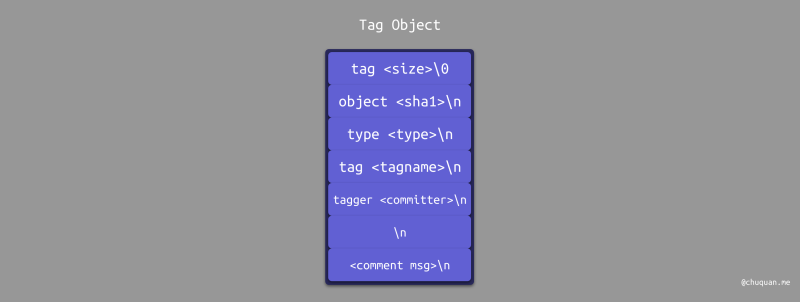
Tag Object 通常指向一个 Commit Object,而不是 Tree Object。它像是一个永不移动的分支引用——永远指向同一个 Commit Object,只不过给这个 Commit Object 加上一个更友好的名字罢了。
我们可以通过 analyze-git
来查看一个附注标签所创建的 Tag Object。 1
2
3
4
5
6
7
8
9
10$ cat .git/resfs/tags/v1.1
163827fe0e0a63112bee25a48bdcca2de89982e3
$ git cat-file -p 163827fe0e0a63112bee25a48bdcca2de89982e3
object e73b484c6e1802c36dceae4535f6c8517716650c
type commit
tag v1.1
tagger baocq <baocq@fenbi.com> 1652526376 +0800
test tag
我们可以看到 Tag Object 的 object 字段为我们打了标签的的 Commit Object 的 SHA-1 值。从 Tag Object 的内容定义上能看出,Tag Object 并非必须指向某个 Commit Object;我们可以对任意类型的 Git 对象打标签。比如,在 Git 源码中,项目维护者将他们的 GPG 公钥添加为一个数据对象,然后对这个对象打了个标签。我们可以在 Git 源码仓库下执行以下命令查看。
1 | $ git cat-file blob junio-gpg-pub |
远程引用
远程引用(Remote
Reference)主要用于远程仓库与本地仓库进行映射和对比。如果我们添加了一个远程仓库并对其执行过推送操作,Git
会记录下最近一次推送操作时每一个分支所对应的值,并保存在
.git/refs/remotes/ 目录下。
远程引用和分支(位于 .git/refs/heads/
目录下的引用)之间的最主要区别在于:远程引用是只读的。虽然我们可以
git checkout 到某个远程引用,但是 Git 并不会将 HEAD
引用指向该远程引用。因此,我们永远不能通过 git commit
命令来更新远程引用。Git
将这些远程引用作为记录远程服务器上各个分支最后已知位置状态的书签来管理。
包文件
通过上文我们知道,如果我们对任意一个文件进行修改,Git 就会创建一个新的 Blob Object,并将该文件的所有内容存储到里面。那么这时候问题来了,如果一个文件非常大,而每次我们只修改其中极小一部分内容,这样的话,Git 会创建很多 Blob Object,而它们的绝大部分的内容都是相同的,因此会存在严重的磁盘空间浪费问题。如果 Git 只完整保存其中一个,在保存另外一个对象与之前版本的差异内容,岂不是更好?
对于这方面的优化,Git 的确采用了增量存储的方式进行了优化。那么具体怎么做的呢?
事实上,Git 会不定时地自动对仓库中的对象进行打包并移除,最终生成两个文件:
- 包文件(Pack File) :采用 原始内容 + 增量内容 的形式进存储,从而节省存储空间。
- 索引文件(Index File):存储了各个包文件中各个对象的大小、偏移、类型等数据,从而便于重建文件快照和对象关系。
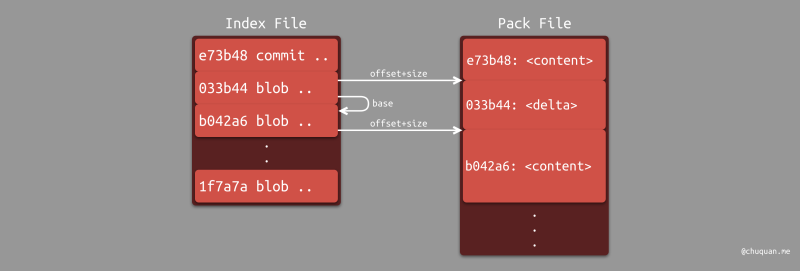
我们可以使用 git verify-pack 这个底层命令来查看 analyze-git
中的索引文件。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20$ git verify-pack -v .git/objects/pack/pack-b850d8225332999ae75a6a83e36c4729173c1e8d.idx
92261eb83bf2bf5da2a0b2ca5e88d4099ee2b71f commit 217 150 12
3103a76a8bc9daea112a4fdbee03f8c5686d8f86 commit 208 144 162
e73b484c6e1802c36dceae4535f6c8517716650c commit 207 143 306
a9f2652cb992f300c0a251d3607bdabfe8901bb2 commit 208 142 449
163827fe0e0a63112bee25a48bdcca2de89982e3 tag 126 117 591
bc36caf5d579e4275ec0c8b32a6d620b99d37e8d commit 159 112 708
fe879577cb8cffcdf25441725141e310dd7d239b tree 136 136 820
d8329fc1cc938780ffdd9f94e0d364e0ea74f579 tree 36 46 956
deef2e1b793907545e50a2ea2ddb5ba6c58c4506 tree 136 136 1002
3c4e9cd789d88d8d89c1073707c3585e41b0e614 tree 8 19 1138 1 deef2e1b793907545e50a2ea2ddb5ba6c58c4506
0155eb4229851634a0f03eb265b69f5a2d56f341 tree 71 76 1157
83baae61804e65cc73a7201a7252750c76066a30 blob 10 19 1233
fa49b077972391ad58037050f2a75f74e3671e92 blob 9 18 1252
b042a60ef7dff760008df33cee372b945b6e884e blob 22054 5799 1270
033b4468fa6b2a9547a70d88d1bbe8bf3f9ed0d5 blob 9 20 7069 1 b042a60ef7dff760008df33cee372b945b6e884e
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 10 19 7089
non delta: 14 objects
chain length = 1: 2 objects
.git/objects/pack/pack-b850d8225332999ae75a6a83e36c4729173c1e8d.pack: ok
- SHA-1:对象的 SHA-1 值
- type:对象的类型
- size:对象的大小
- size-in-packfile:对象在包文件中的大小
- offset-in-packfile:对象在包文件中的偏移
- depth:对象在包文件所处的索引关系中的深度
- base-SHA-1:增量对象的父级对象的 SHA-1 值
关于包文件,Git 经常自动进行打包来节省空间,当然我们也可以手动执行
git gc
命令来进行打包。注意,当我们执行将代码推送至远程仓库时,Git
也会进行打包。我们可以看到 git push 或
git pull 时控制台输出的打包相关的信息,如下所示。
1
2
3
4
5
6
7
8
9
10
11$ git push -u origin master
Enumerating objects: 7, done.
Counting objects: 100% (7/7), done.
Delta compression using up to 4 threads.
Compressing objects: 100% (5/5), done.
Writing objects: 100% (6/6), 6.27 KiB | 6.27 MiB/s, done.
Total 6 (delta 1), reused 6 (delta 1)
remote: Resolving deltas: 100% (1/1), done.
To https://github.com/baochuquan/analyze-git.git
e73b484..92261eb master -> master
Branch 'master' set up to track remote branch 'master' from 'origin'.
基于底层原理的应用
关于 Git 底层原理的应用例子其实很多,这里我们来介绍一个 CocoaPods Source 管理机制的例子。
下图所示为 CocoaPods Source 管理机制的 Master
方案。Specs 目录下为什么要细分出来多级子目录?
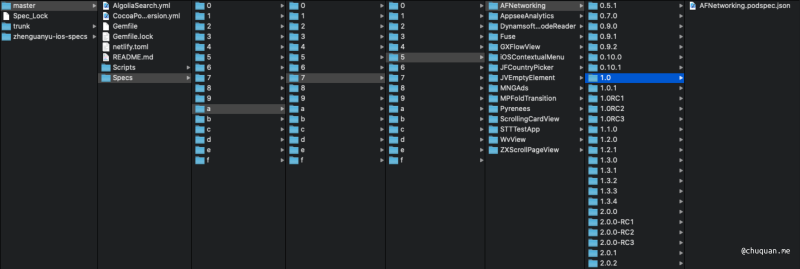
这样设计的目的为了在 Git 版本变更时尽可能少地增加 Git 对象体积。假设,有个 Git 仓库包含 100 个文件,我们使用两种方式进行管理:
- 分级管理:两级目录,根目录下有 10 个子目录,每个子目录下 10 个文件。
- 扁平管理:100个文件全部放在根目录下。
我们分别计算一下两种方案下版本变更时,产生的 git 对象体积。
下图所示为分级管理的情况下,修改一个文件所产生的对象示意图。新增的数据包括:1 个 Commit Object、2 个 Tree Object、1 个 Blob Object。两个 Tree Object 总共包含 20 个记录项。新建两个 Tree Object 总共需要遍历 10 + 10 个对象即可。
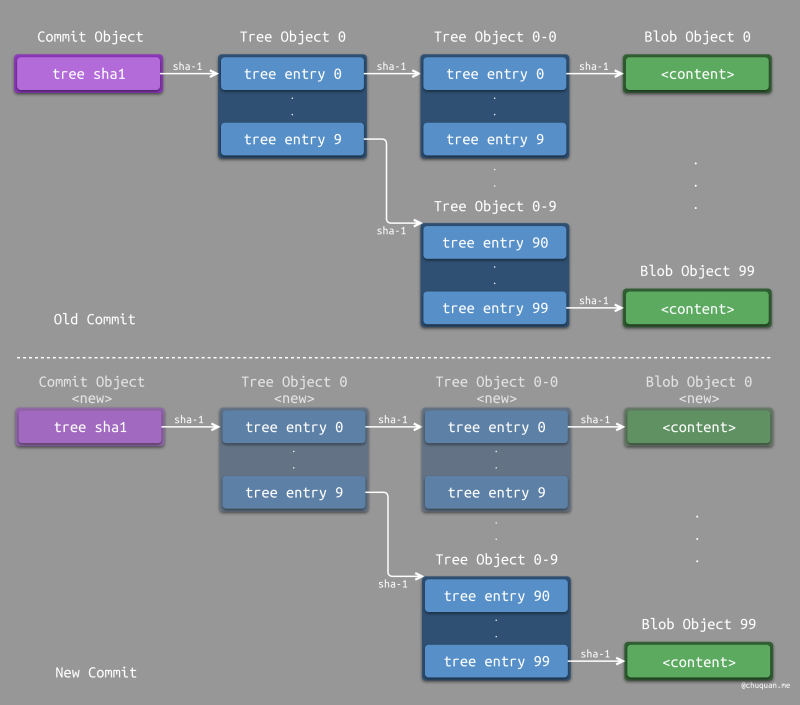
下图所示为扁平管理的情况下,修改一个文件所产生的对象示意图。新增的数据包括:1 个 Commit Object、1 个 Tree Object、1 个 Blob Object。虽然新增的 Tree Object 数量少,但是新增的 Tree Object 的记录项非常多,有 100 个。此外,新建这个 Tree Object 需要遍历 100 个对象。
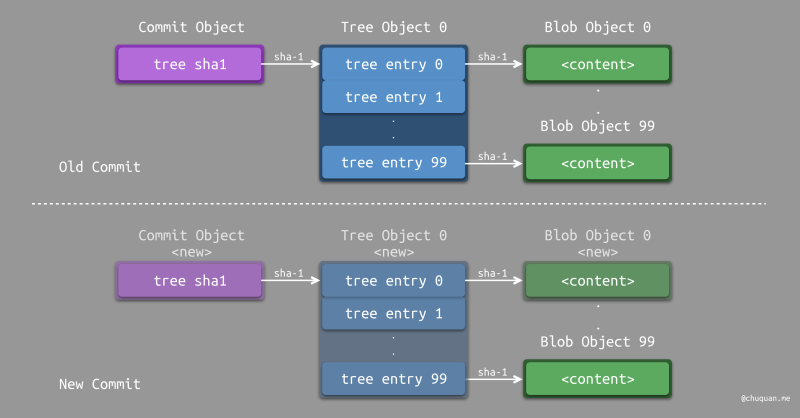
对比之下,我们可以发现分级管理虽然产生的对象多,但是实际占用的空间反而是更小的,并且新建对象时遍历的对象更少,效率更高。
总结
本文主要介绍了 Git 的底层实现原理,首先是其架构,大概分为三层,分别是:上层命令、底层命令、对象数据库(内容寻址文件系统)。
我们重点介绍了对象数据库,使用 Linux Ext 文件系统跟它进行了对比,两者在设计理念上基本是一致的。整个设计理念非常清晰,将文件和目录进行区分存储。使用轻量级数据结构表示目录可以在某些场景下提升效率,比如重命名等。
关于底层数据,我们介绍了其核心的 4 种:Blob Object、Tree Object、Commit Object 以及 Tag Object。这些对象各司其职,在底层支持了 Git 的设计理念。
最后,我们介绍了一个真实的设计案例——CocoaPods Source 管理机制,其正是应用了 Git 的底层原理对自身系统进行了性能优化。未来,我们在设计自己的软件时,也可以借鉴 Git 底层原理进行优化。