
每年总是要例行回顾一下过去一年,看看自己做了什么,收获了什么。
角色适应
今年是作为移动客户端负责人的第 2 年,自己基本已经适应了这个角色。一开始,我和团队中很多成员都是一线的研发,后面被提拔到这个位置。那时候,在技术决策、任务分配、会议沟通时,经常会想自己的决策和做法是否被认可?是否被信服?团队成员是否认可自己?总之,心理负担一直都是有的。
在业务的迭代和发展过程中,我会回顾自己做的决策。从结果看来,整体都是符合预期的,比如:
- 关于兄弟团队借人的决策。部门内有两条业务线,另一条业务线今年年初在快速发展,缺 iOS 开发,于是经过部门老大的同意向我们借人,希望能够支援 3 个月。,最终我决定让组内的几个同学轮流支援,每人支援一个月。一方面,可以避免外派同学产生边缘心理;另一方面,也可以避免借人还人的情况。
- 关于提测质量竞赛的决策。年初在与测试同学的沟通中了解到:在服务端、前端、客户端的测试过程中,测试体验最差的往往都是客户端。当然,这里面是存在客观原因的。关于服务端,其主要是开发业务逻辑,不包含 UI 逻辑,一旦联调完毕,在测试阶段 BUG 其实是很少的;关于前端,其与客户端非常相似,区别在于前端在测试阶段可以热修复 BUG,前一分钟还存在的 BUG,后一分钟可能就解决了。关于客户端,相比服务端多了 UI BUG,相比前端修复周期比较长(修复、编译、验证、打包、提测)。最终产生客户端测试体验差的感觉。为了提高提测质量,提出了提测质量竞赛的机制,对于同一个需求,Android/iOS BUG 数量出现大于等于 5 的情况时,BUG 数量少的一方和对应的测试同学将获得一杯喜茶,并记录在 Score Board 中。一年下来,组内成员的自测意识确实提高了不少,产生的 BUG 基本上都是测试用例之外的 BUG。
正确的决策会带来正向的激励,从而产生正反馈效应。于是,之前心理负担开始慢慢的消失,自己对于这个角色也开始逐步适应,慢慢开始变得得心应手起来。
工作产出
在工作产出方面,今年主要做了一些工程能力和技术调研等工作,比如:
- 构建客户端 NodeJS 服务,支持 Sentry 崩溃告警、GitLab Code Review、包体积分析等能力。
- Cocos 引擎定制的工程化,解决底层引擎替换问题,增加引擎日志,独立引擎打包等。
- 推进并落地 Cocos 资源代码隔离能力,从而让 App 内的 Cocos 互动题具备全局的热修复能力。
- 直播自建、局部录屏、恢复购买、家庭共享、Deferred Deep Link 等技术方案调研。
今年,在 iOS 同学外派支援期间,我做了一些业务需求,其他时间基本都没有参与复杂业务和模块的具体开发。因为团队内 Android 和 iOS 的研发人员数量对等,所以不需要我来承担额外的开发任务。只有当出现临时需求或者排期时没有分配的需求时,为了不打乱既定的排期,一般会由我来兜底做这些需求,一个人同时写 Android 和 iOS。
整体而言,今年开始逐步退居二线,做一些技术决策和工程能力等相关工作。不过,在日常中我仍然坚持写代码,因为我始终觉得一旦自己脱离一线太久,很容易会作出一些不符合现实的决策和排期。
身体是革命的本钱
眼睛疲劳
从 2021 年下半年到 2022 年上半年,我一直有着眼睛疲劳的症状,具体表现就是 眼睛无法准确对焦。当我在观察 3 米以外的物体时,大脑中呈现的视觉效果是有两个物体(两个眼镜各自成像的物体),两个物体无法合成到一个画面中,需要非常努力的弄眉挤眼才能对焦上,但是过不了多久又会失焦。
这个问题我一直都没有发现,因为在工作生活中,眼睛对焦基本都在 3 米以内。最后是在电影院观影时才发现的,画面有重影,观影感极差。从那时起,我才开始重视视力问题。
在 4 月份,我预约了同仁医院的眼科挂号。在医院里,我看到了各种饱受眼科疾病困扰的患者,青光眼、视网膜脱落、近视手术后遗症等等,这让我视力恢复之前都非常焦虑。在经历一系列眼科诊断之后,医生得出的结论是眼睛疲劳 + 近视度数上涨。于是,在同仁医院配了一副眼镜,自己额外配了一副隔蓝光的镜片,配合着服用叶黄素,进行修养。总体来说,是有效果的,但是效果还是有点慢。

在 5 月份,五一长假休假在家,我尝试尽量不使用电脑和手机。即使使用电脑,也是投屏到电视上,然后坐在沙发上观看电视屏幕,尽量保持远距离观看。经过一个多星期的调养。眼睛疲劳改善非常明显。假期结束后,我期望着眼睛能完全恢复,可惜大概一个月作用的时间,眼睛又开始疲劳。特别是中午遇到强光时,症状会更加严重。
在 8 月份,我开始意识到眼睛疲劳可能是因为睡前和醒后躺在床上刷手机导致的。每次睡觉前我都会不由自主地刷一个多小时的手机,早上醒来也是躺在床上刷一个多小时手机,加上姿势不正确,导致视力疲劳。于是,我开始强制自己在床上玩手机不超过 20 分钟。坚持了半年了,现在视力明显恢复了。
在视力恢复之前,我一度非常焦虑,经常思考程序员的职业给我带来了什么?如果视力无法治疗该怎么办?…好在现在恢复了,这次经历让我明白了身体健康的重要性。一定要注意身体,不要让打工挣的钱成为身体的医疗费!从而言之,身体是革命的本钱。
运动健身
健身
8 月份,在 @昱总 的安利下,我办了天奥的健身卡,怕自己坚持不下来,先办了一年的年卡。由于 8 月份期间参加各种篮球赛,所以真正开始规律健身应该是从 9 月份开始,周一练背,周四练肩,周五练手臂,偶尔练练卧推。目前卧推能 60KG 做组,左右手力量也均衡了很多。除此之外,双十一配了肌酸和蛋白粉,喝的不算多,佛系健身。于我而言,健身的目的是为了自己变得壮一点,而不是看起来像细狗,仅此而已,什么健体、健美并不是我的目标。
篮球
今年算是工作以来打篮球最多的一年了,首先是固定每周二中午打 2 小时篮球。另外就是篮球赛,8 月参加了 CBD 篮球联赛,9 月参加了 CYBA 篮球联赛,这两个月周末总有一天是在打篮球。


跑步
2022 年终总结时给自己定了一个目标——参加一次半程马拉松。因此,我计划参加 4 月份的北京半程马拉松。结果,等到报名时发现要求必须三年内参加过其他马拉松,并提供相关证明。没办法,没有资格参加,只能选择参加奥森马拉松。
我从 2.25 开始备战,从 5 公里开始,每周跑一次,每次比上一次增加 2.5 公里左右,最终达到 21 公里。练了一次 21 公里后,参加比赛。最终成绩还不错,用时 2:01:52。定一个 2024 年的小目标——半马破 2 小时。

参加半马之后,我开始坚持每周末都跑一次 10 公里,偶尔还会参加一下线上马拉松,收集了不少奖牌。最终坚持到了 10 月底,11 月份室外跑步属实太冷了,打算 2 月份重新开始。

作息
正是办了健身卡之后,我和媳妇开始调整生活作息,拒绝熬夜,晚上 11:20 之前睡觉。早上差不多能 6、7 点起床,起来后去四得公园,媳妇跑步,我则散步。在公园大概 40 分钟,期间能呼吸一下新鲜空气,放空一下大脑。当然在一个人散步的时候会思考很多,比如:职业规划、业余项目、技术问题等。散步结束回来大概 8 点左右,还能有两个小时看会儿书或写会儿代码。
调整作息之后,感觉自己的精神状态好了很多,下班时间的使用效率也变得更高了。当然,周末也不再是没有上午的周末,时间也变得更加充足。作息调整是今年个人转变的最大成就,为了健康和效率,未来一直要继续保持下去。
学习收获
上半年因为眼睛问题,有意减少电脑使用时间,下半年业余时间主要在项目,因此整体而言,2023 年在学习上投入的时间并不是很多。关于学习方面的成就主要有以下几部分。
书籍
因为尽量不过度用眼,今年看的书并不多,只有以下几本:
- 《第一行代码——Android(第3版)》
- 《架构师的自我修炼》
- 《程序员修炼之道》
- 《On Java 基础版》
- 《重构》
- 《程序员的自我修养》三刷
- 《计算机图形学入门:3D渲染指南》
博客
今年写的博客也不多,年初的时候产出了几篇编程语言相关的博客:《浅谈 Actor 模型》、《结构化并发》、《基于原型的继承模式》。
年中的时候研究 Homebrew 和 fishhook 产出了两篇原理分析博客:《如何从链接原理的角度理解 fishhook 的设计思想?》、《Homebrew 的设计哲学》。
最后就是十一那会儿写了两篇关于差分算法的博客:《Myers 差分算法
》、《Paul Heckel 差分算法》。
项目
今年业余时间总共做了三个半项目,相比之前几年,产出高出了不少,希望明年继续保持。
第一个项目是 Taskloop。这是一款基于 crontab 的定时任务管理器,支持语义化的配置规则,并且支持环境变量导入、日持查询等功能。具体介绍详见 《如何优雅地管理你的定时任务?》。
![]()
第二个项目是 Morph Clock(中文名:莫负时钟)屏幕保护程序。这是一款 MacOS 屏幕保护程序,采用一种数字变形的艺术效果实现。
第三个项目是 Morph Rest(中文名:莫负休息)。这是一款 MacOS 休息提醒应用程序,预防眼睛疲劳、腰间盘突出、劲椎疼痛等职业病,也可辅助提醒喝水,避免尿酸过高,引发痛风等疾病。为什么做这个项目?主要有两方面原因:一方面,我经历了眼睛疲劳,迫切需要一款软件能够经常提醒我站起来活动活动,让视线远离屏幕,顺带提醒自己多喝水。另一方面,我希望打造一款独立产品,尝试利用业务时间成为一位 Indie Hacker。于是,差不多花了一个半月的业余时间,完成了项目,并最终上架。
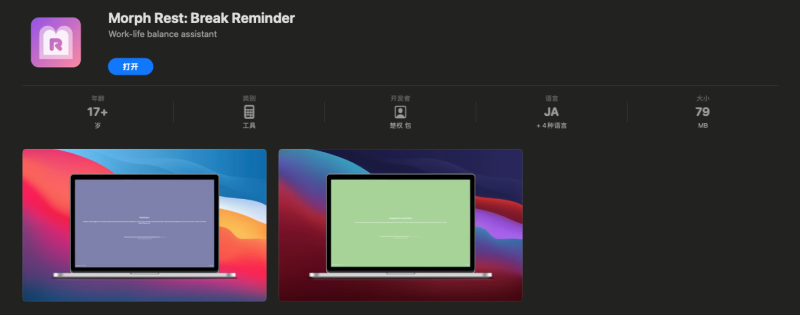
Morph Clock 和 Morph Rest 则是面向普通 Mac 用户的独立产品。项目代码并没有开源,因为我希望能够通过它们创造收入,这里定一个小目标:在未来 2024 年内通过独立产品创造 99 美元的收入,回收的开通苹果开发者账号的成本。如果有用户支持,欢迎下载使用。
其他
其他方面的学习收获也是有的,首先是 Android 开发,春节假期期间,在家学习了一下 Android 开发,重写了海豚 AI 学中的一个 Flutter 页面,算是入门了 Android。鉴于此,下半年能够做一些 Android 小需求。但是没有深入研究 Android 开发,也没有做过一些复杂业务开发,这一方面希望 2024 年能够有所改善。
其次,在下半年做独立产品期间,系统性地学习了 Sketch 相关技巧和理论。Morph Rest 和 Morph Clock 相关的 UI 设计和切图也都是自己完成的,算是额外掌握了一个 Indie Hacker 必备的技能吧。
最后,系统性地学习了一下 MacOS 开发,它与 iOS 开发在整体上一致的,在一些实现细节上有所不同。如果按照自己所认知的 iOS 原理来开发 MacOS 应用会遇到很多奇怪的 BUG。在系统性学习之后,再来开发 MacOS 应用会简单很多,这一点我深有体会。
生活不只有工作
今年是工作以来第一个没有债务的年份,因此不再考虑紧巴巴地生活了,该吃吃,该喝喝,该玩玩。不过因为疫情三年养成了一种「宅」感,所以还需要继续调整和适应。
假期
合肥
五一假期回合肥休假,为了调养眼睛疲劳,没怎么学习,主打的就是休假。期间主要在滨湖转悠,骑上共享电驴,环游了一些景点和公园,渡江战役纪念馆、岸上草原、安徽名人馆、塘西河公园、金斗公园等。比较可惜的是,没约上安徽美术馆,不过以后有的是机会。
在家期间,用闲置的 Mac Mini 配上电视,效果很不错,也很护眼。用这一套装置在家看完了《漫长的季节》!《漫长的季节》成为了我心中国产剧的 No.1,墙裂推荐!

廊坊
7 月份,我在朋友圈看到有同事去了廊坊的只有红楼梦·梦幻戏剧城,感觉很不错,加上自己很喜欢《红楼梦》,所以抽了一个周末去了一趟廊坊。园区非常大,网上的评价大多是一天的游玩时间不够,于是我们就订了 2 日通票。不得不说,里面的建筑和剧场都非常惊艳!绝对值得去玩一次!
不过很可惜,我们去的那个周末天气不太好。周六阴天,周日暴雨。因为暴雨园区闭园,给我们退了一半的票,算下来也就是玩了一天时间,差不多玩了大半个园区吧,只不过话剧和情景剧没看够。


哈尔滨
今年 10 月份原本打算去哈尔滨,结果跟我弟了解了一下情况后,决定等到冰雪大世界开放之后再去。最终在元旦前请了几天假提前出发,主要是为了避开假期旅游高峰。好巧不巧,哈尔滨旅游今年出圈了,游客非常多,几个热门项目排队时间都超长,几乎每个都要排队 3 个小时起步,比如:大滑梯、摩天轮、哈冰秀。我们在冰雪大世界整一天就是佛系游玩,毕竟在零下十度的室外排队几个小时的体验可不是那么好。不过有一说一,冰雪大世界里的冰雕、雪雕确实都非常精美、壮观,绝对值得去参观一次!


搬家
今年 10 月份搬了一次家,离开了住了 6 年的高家园。高家园附近环境其实很不错,小区门口很多街边商店,很繁华;马路对面就是丽都,是一个相对比较高端的街区;500 米远处是四得公园,疫情期间翻修了一次,环境非常不错。因为生活很方便,所以在这里住了 6 年。搬家期间,特别是对面的室友搬走的时候,内心非常感慨:岁月匆匆,人生匆匆,北漂生活何时终了?

思维转变
2023 年,我感觉自己最大的变化是思维的转换,主要是两点:
- 身体是最重要的,其他的一切都是身外之物。
- 打工是没有出路的,提前计划自己的未来。
第一点不用多说,是眼睛疲劳期间非常焦虑,那会儿才真正体会和理解这一点。第二点是因为今年 8 月开始早起散步,散步期间开始思考未来的打算。这两年各种裁员消息层出不穷,即使你学历再好,技术再厉害,当公司不需要你时,无外乎其他任何因素,随时都可能裁你。一旦失业,你再就业的难度会与你的年龄正比,这是非常现实的问题。
于是,我开始逛一下独立开发者相关的网站,比如:Indie Hacker,Product Hunt,w2solo。在这些论坛中,我看到了很多独立开发者的成功案例,这也激励了我尝试使用业余时间来走这条道路。11 月份,我开始着手做一款 iOS App,期间自己做产品调研,画设计稿,代码实现。期间感觉自己对于产品的最终效果还是有点不确定,而且担心战线太长,所以果断暂停了项目,转而开发形态更加确定的一款 MacOS App——MorphRest。期间,还写了一个 MacOS 屏幕保护程序——Morph Clock。这些产品未来不一定能成功,但是我不迈出这一步,那么永远都不会成功。
新年愿景
未来一年,我应该还会继续尝试做一些独立产品,努力成为 Indie Hacker。当然,技术博客也会被不定期更新,毕竟这是热爱,而不是生活。
最后,祝新年快乐~
]]>