
Swift 泛型底层实现原理
在《Swift 性能优化(2)——协议与泛型的实现》中我们介绍了 Swift 是如何管理协议类型与泛型类型的生命周期与方法调用。本文我们将进一步介绍 Swift 泛型的底层实现原理。
回顾
协议类型在内存中的存储形式是 Existential Container,Existential Container 占 5 个内存单元(也称 词),其作用如下:
- 3 个词作为 Value Buffer。
- 1 个词作为 Value Witness Table 的索引,主要用于管理生命周期。
- 1 个词作为 Protocol Witness Table 的索引,主要用于管理方法调用。

泛型类型由于在调用时能够确定具体的类型,所以不需要使用 Existential Container。在调用泛型方法时,只需要将 Value Witness Table/Protocol Witness Table 作为额外参数进行传递。
内存管理
泛型类型使用 VWT 进行内存管理,VWT 由编译器生成,其存储了该类型的
size、aligment(对齐方式)以及针对该类型的基本内存操作。其结构如下所示(以
C 代码表示): 1
2
3
4
5
6
7
8struct value_witness_table {
size_t size, align;
void (*copy_init)(opaque *dst, const opaque *src, type *T);
void (*copy_assign)(opaque *dst, const opaque *src, type *T);
void (*move_init)(opaque *dst, const opaque *src, type *T);
void (*move_assign)(opaque *dst, const opaque *src, type *T);
void (*destroy)(opaque *val, type *T);
}
当对泛型类型进行内存操作(如:内存拷贝)时,最终会调用对应泛型类型的 VWT 中的基本内存操作。泛型类型不同,其对应的 VWT 也不同。下图所示为一个小的值类型和一个引用类型的 VWT。
对于一个小的值类型,如:integer。该类型的 copy 和 move 操作会进行内存拷贝;destroy 操作则不进行任何操作。
对于一个引用类型,如:class。该类型的 copy 操作会对引用计数加
1;move 操作会拷贝指针,而不会更新引用计数;destroy
操作会对引用计数减 1。

方法调用
上一节,我们介绍了泛型的内存管理。那么,泛型的方法调用又是如何实现的呢?
我们以如下一个泛型函数为例进行介绍。 1
2
3
4func f<T>(_ t: T) -> T {
let copy = t
return copy
}
编译器对上述的泛型函数进行编译后,会得到如下代码(以 C 代码代替 LLVM
IR)。 1
2
3
4
5
6
7// T: 泛型参数
void f(opaque *result, opaque *t, type *T) {
opaque *copy = alloca(T->vwt->size);
T->vwt->copy_init(copy, t, T);
T->vwt->move_init(result, copy, T);
T->vwt->destroy(t, T);
}type *T。很明显,这是一个类型参数,描述泛型类型所绑定的具体类型的元信息,包括对
VWT 的索引信息。
f<T>
是一个对泛型类型进行拷贝的方法,囊括了上述介绍的内存管理的过程,下面我们来简要分析其编译后的源码:
- 局部变量是分配在栈上的,并且对于该类型,我们不知道要分配多少内存空间,所以需要通过
VWT 获取到
T的size才能进行内存分配。 - 内存空间分配完之后,通过 VWT 中的
copy方法,以输入值t来初始化局部变量。 - 局部变量初始化完毕之后,通过 VWT 中的
move方法,将局部变量移到result缓冲区以返回结果。 - 返回时,通过 VWT 中的
destroy方法销毁局部变量。
上述泛型函数的实现中,type *T
是整个函数能够顺利运行的关键。那么 type *T
到底是什么呢?
Type Metadata
事实上,编译器在会尽量在编译时为每一个类型生成一个类型元信息对象——Type
Metadata,也就是上述的 type *T。
Type Metadata 携带的类型元信息主要包含:类型的 VWT、类型的反射信息。如下图所示:
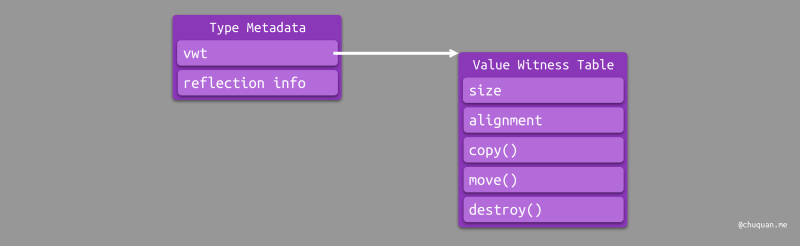
《Swift 性能优化(2)——协议与泛型的实现》文中提到每个对象初始化时就有的
type 字段其实就是 Type Medata 对象。因此对于不使用
Existential Container 进行表示的泛型类型来说,通过 Type Metadata
也可以索引到 VWT。
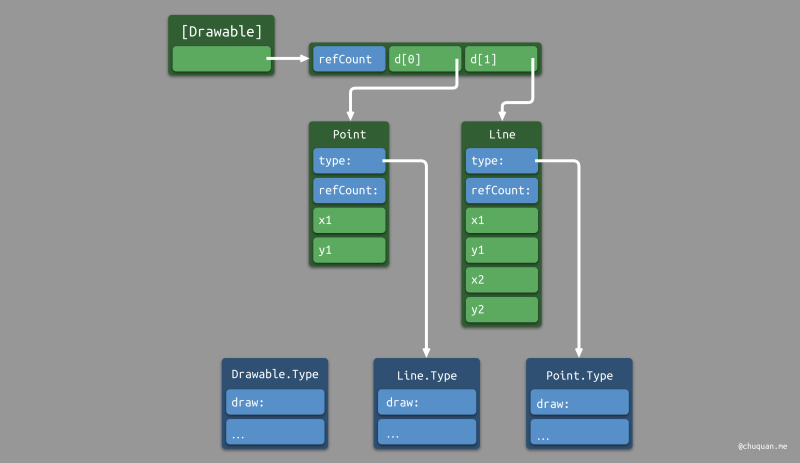
每一种类型,在全局只有一个 Type Metadata,供全局共享。
对于内建基本值类型,如:Integer,编译器会在标准库中生成对应的
Type Metadata 和 VWT。其中,VWT 是针对小的值类型 VWT。
对于引用类型,如:UIView,编译器也会在标准库中生成 Type
Metadata 和 VWT。其中,VWT 是针对引用类型的标准 VWT。
对于自定义的引用类型,Type Metadata 会在我们的程序中生成,VWT 则由所有引用类型共享,即上述针对引用类型的标准 VWT。

下面,我们再以上述 f<T>
函数的具体调用来进行介绍编译后的代码是如何使用 Type Metadata
的。如下所示为两种类型对 f<T> 的调用。 1
2
3
4
5
6f(123)
struct MyStruct {
var a, b, c, d: UInt8
}
f(MyStruct())int 类型和 MyStruct 类型调用
f<T> 时,编译器生成的代码如下所示: 1
2
3
4
5
6
7int val = 123;
extern type *Int_metadata;
f(&val, Int_metadata);
MyStruct val;
type *MyStruct_metadata = { ... };
f(&val, MyStruct_metadata);int 类型使用标准库中的 Type
Metadata;自定义类型则使用针对自身生成的 Type Metadata。
事实上,上述 Type Metadata 之所以能够在编译时生成,是因为我们在调用时就能通过类型推导得出其类型。如果,在调用时无法推断其类型,则需要在运行时动态生成 Type Metadata。
为了了解 Type Metadata 的动态生成,我们需要先了解 Metadata Pattern。
Metadata Pattern
事实上,对于泛型类型,编译器会在编译时生成一个 Metadata Pattern。Metadata Pattern 与 Type Metadata 的关系其实就是类与对象的关系。
以如下自定义泛型类结构为例。 1
2
3
4struct Pair<T> {
var first: T
var second: T
}
对于运行时才能确定的泛型类型,运行时根据绑定类型的 Type Metadata,结合 Metadata Pattern,生成最终的确定类型的 Type Metadata。如下图所示:
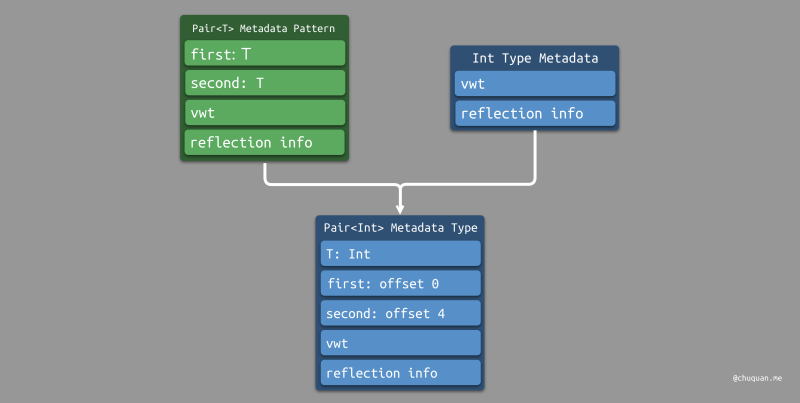
对于 Pair<Int>,运行时会计算
Pair<Int> 的
size,并计算出各个域的偏移。
下面,我们通过一个泛型属性访问的例子来看看运行时是如何使用 Metadata
Pattern 来生成 Type Metadata。以如下代码为例: 1
2
3func getSecond<T>(_ pair: Pair<T>) -> T {
return pair.second
}1
2
3
4
5
6void getSecond(opaque *result, opaque *pair, type *T) {
type *PairOfT = get_generic_metadata(&Pair_pattern, T); // 实例化 type metadata
const opaque *second = (pair + PairOfT->fields[1]);
T->vwt->copy_init(result, second, T);
PairOfT->vwt->destroy(pair, PairOfT);
}
- 运行时,根据 Metadata Pattern,结合绑定的类型
T的 Type Medata(如 Int Type Metadata)生成Pair<T>的 Type Metadata 实例。 - 根据
Pair<T>的 Type Metadata 获得second在内存中的位置。 - 拷贝
second躲在位置的内存到result缓存区。 - 返回前,销毁局部变量。
编译优化
上述代码是在编译时无法推断出泛型类型的情况下生成的通用型代码。然而,如果在编译时就能推导出泛型类型,编译器则会进行优化,在真正运行时避免通过传递 Type Metadata 来查找各个域的偏移,从而提高运行性能。
如下代码,就可以在编译时进行类型推导。 1
2
3func getSecond(_ pair: Pair<Int>) -> Int {
return pair.second
}
高阶函数
下面,我们再来看看高阶泛型函数是如何进行编译的。 1
2
3func apply<T>(value: T, fn: (T) -> T) -> T {
return fn(value)
}1
2
3
4
5
6
7void apply(apaque *ret,
opaque *value,
void (*func_invoke)(opaque *ret, opaque *arg, void *context),
void *fn_context,
type *T) {
fn_invoke(ret, value, fn_context);
}
其中,func_invoke
是闭包的函数指针,由于闭包可以捕获外部作用域,入参 context
就是用于传递作用域上下文。
为了调用闭包,执行 fn_invoke(ret, value, fn_context)
就是调用函数执行,并将上下文 fn_context
作为参数传进去。
下面,我们来看一个调用 apply<T> 的例子。
1
apply(0, { $0 + 1 })
1
2
3
4
5
6Int closure(Int $0) {
return $0 + 1;
}
apply(..., closure, NULL, ...);
// we have: Int (*func_invoke)(Int arg, void *ctxt)
// we need: void (*func_invoke)(opaque *ret, opaque *arg, void *ctxt)Int (*func_invoke)(Int arg, void *ctxt) 闭包直接传递到
apply 中,而是需要将已确定类型的闭包转换成
void (*func_invoke)(opaque *ret, opaque *arg, void *ctxt)
闭包的形式间接传递到 apply 中。
那么,在确定类型的情况下,这里为什么仍然要做一次间接的转换与传递呢?
对此,我们需要首先介绍一个概念——重抽象(Reabstract)。
Reabstract
Swift 中的所有类型都存在多个抽象级别。比如:一个 Int
值是一个具体类型,可以传递给确定类型的函数。但是 Int
值也可能传递给类型为泛型 T
的函数,此时该泛型函数希望能够间接接收该参数,从而适应其他可能的泛型类型,如:Float、String
等。当 Int 值传递给泛型函数时,它被认为比其为
Int
时处于更高的抽象级别。这种在抽象级别之间进行转化的过程被称为是
重抽象。
计算机科学中的每个问题都可以用一间接层解决。
事实上,上述 apply
采用间接传递的思想,本质上就是为了实现对类型进行重抽象的一种抽象模式。
这里通过 thunk
来实现对闭包的值进行重抽象,从而匹配函数的抽象模式。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16Int closure(Int $0) {
return $0 + 1;
}
void thunk(Int *ret, Int *arg, void *thunk_ctxt) {
// 1. 从 thunk 上下文中获取原始的 函数指针
Int (*fn_invoke)(Int, void*) = thunk_ctxt->...;
// 2. 从 thunk 上下文中获取原始的 context
void *fn_context = thunk_ctxt->...;
// 3. 在调用函数前,我们将需要间接的结果转换为直接的结果,通过 *arg。
// 4. 最后将 fn_invoke 返回的直接值转换为间接值,通过 *ret =
*ret = fn_invoke(*arg, fn_context);
}
void *thunk_ctxt = allocate(..., closure, NULL); // allocate a context
apply(..., thunk, thunk_ctxt, ...);
总结
到此,我们对 Swift 泛型的底层实现有了一定的理解了。那么协议的底层实现又是如何呢?其实,本质上协议就是受约束的泛型,具体的实现思想和形式也和泛型差不多。
参考
- TypeMetadata
- Generics in Swift
- Abstraction-levels
- Lowering Higher-Order Functions
- LLVM Developer’s Meeting: “Implementing Swift Generics”.