
Myers 差分算法
差分算法(Difference Algorithm)是一种数值计算方法,其主要用于解决两个数据集之间的差异问题,通过计算两个数据集之间的差异,取代对整个数据集的处理。
差分算法的应用非常广泛,主要有以下这些应用领域:
- 数据压缩:差分算法可以用来检测和删除冗余数据,从而实现数据的压缩。比如,对于一段音频数据,如果相邻的数据点之间的值几乎没有变化,那么就可以用差分值来代替原始数据,从而大大减小数据的大小。
- 版本控制:差分算法可以用来比较不同版本的源代码,以便开发者能够知道哪些部分被修改了。比如:git、svn 等版本控制工具。
- UI 框架:差分算法可以用来比较两个状态的界面树,并找到最少的更新操作,从而高性能刷新界面。比如:SwiftUI、IGList、React、Flutter 等 UI 框架。
本文,我们将深入探讨广泛应用在各种版本控制工具中的差分算法——Myers 差分算法。
最长公共子序列
在介绍 Myers 算法之前,我们先来了解一下著名的 最长公共子序列(Longest Common Subsequence,LCS) 问题。我们引用一下 LeetCode 中的问题描述,如下所示。
1 | 给定两个字符串 text1 和 text2,返回这两个字符串的最长「公共子序列」的长度。如果不存在「公共子序列」,则返回 0 。 |
对于 LCS 问题,经典思路是使用动态规划来解决。动态规划的核心思想是 将一个大问题拆分成多个子问题,分别求解各个子问题,基于各个子问题的解推断出大问题的解。与分治、递归相比,动态规划会记录各个子问题的解,避免重复运算,以空间换时间,从而实现对时间复杂度的优化。下面,我们来介绍一下 LCS 的动态规划解法。
假设字符串 \(text1\) 和
text2 的长度分别为 m 和
n,对此创建一个 m+1 行 n+1
列的二维数组 dp,其中 dp[i][j] 表示
text1[0:i] 和 text2[0:j]
的最长公共子序列的长度。
上述表示中,
text1[0:i]表示text1的长度为i的前缀,text2[0:j]表示text2的长度为j的前缀。
考虑动态规划的边界情况:
- 当
i = 0时,text1[0:i]为空,空字符串和任何字符串的最长公共子序列的长度都是0,因此对任意0 ≤ j ≤ n,有dp[0][j] = 0; - 当
j = 0时,text2[0:j]为空,同理可得,对任意0 ≤ i ≤ m,有dp[i][0] = 0。
因此动态规划的边界情况是:当 i = 0 或 j = 0
时,dp[i][j] = 0。
当 i > 0 且 j > 0 时,考虑
dp[i][j] 的计算:
- 当
text1[i-1] = text2[j-1]时,将这两个相同的字符称为公共字符,考虑text1[0:i-1]和text2[0:j-1]的最长公共子序列,再增加一个公共字符即可得到text1[0:i]和text2[0:j]的最长公共子序列,因此dp[i][j] = dp[i-1][j-1] + 1。 - 当
text1[i-1] != text2[j-1]时,考虑一下两种情况:- 情况一:
text1[0:i-1]和text2[0:j]的最长公共子序列 - 情况二:
text1[0:i]和text2[0:j-1]的最长公共子序列 - 对此,计算
text1[0:i]和text2[0:j]的最长公共子序列,应取两项中长度较大的一项,因此dp[i][j] = max(dp[i-1]][j], dp[i][j-1])。
- 情况一:
最终得到如下所示的状态转移方程:
\[ dp[i][j] = \begin{cases} dp[i-1][j-1] + 1, & \text{text1[i-1] = text2[j-1]} \\ max(dp[i-1][j], dp[i][j-1]), & \text{text1[i-1]$\neq$text2[j-1]} \end{cases} \]
根据状态转移方程,我们可以得到如下代码实现:
1 | // C++ |
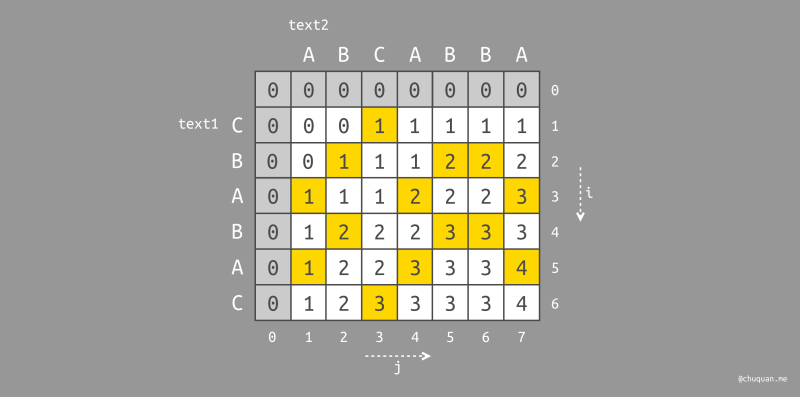
下图所示为二维数组 dp[i][j]
的存储内容,大问题的解由子问题的解推导而出,数组整体从左到右,从上到下推导构建。我们在图中使用黄色标识了
text1[i-1] == text2[j-1]
的情况。此时将从左上角相邻的位置取值并加
1;否则,取左边或上边的相邻值中的最大值。整个二维数组中保存的最大值就是
LCS 问题的解。
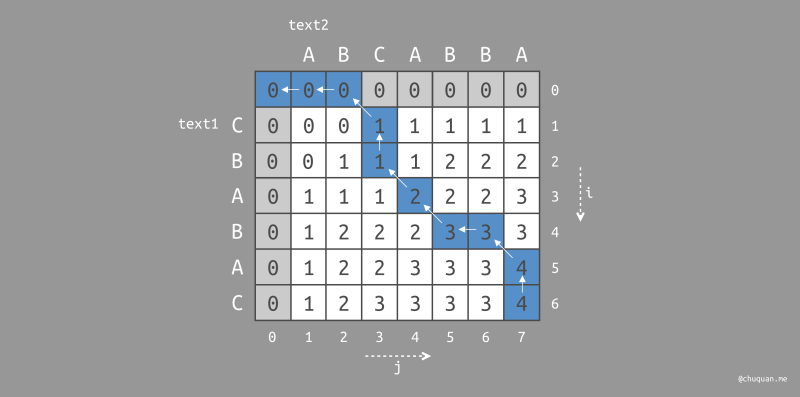
至此我们计算得到了最长公共子序列的长度,然而在实际情况中,我们倾向于得到最长公共子序列本身。此时,可以借助我们构建的二维数组进行回溯。
回溯的方法是:从二维数组的右下角向左上角遍历,当
i = m+1,j = n+1 时可能会遇到三种情况:
- 如果
text1[i] = text2[j],那么向左上角遍历。 - 如果
text1[i] != text2[j],判断dp[i][j]和dp[i-1][j]的值。- 如果
dp[i][j] = dp[i-1][j],则向上遍历; - 否则,向左遍历。
- 如果
由此,我们可以得到如下的遍历路径。
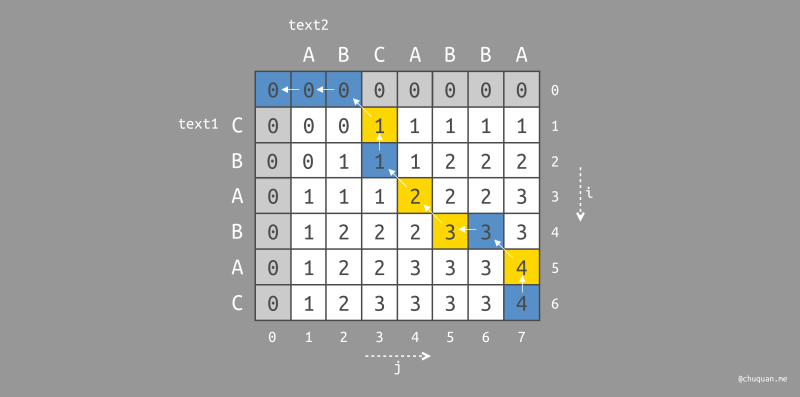
在回溯得到遍历路径之后,我们对路径中向左上角遍历的起始位置进行染色(黄色),即可得到最长公共子序列
CABA,如下图所示。
当然,细心的同学可能会对上述的回溯方法产生疑问:为什么
dp[i][j] = dp[i-1][j]
时向上遍历,而非向左遍历?事实上,如果我们也可以修改回溯方法,得到如下的遍历路径。
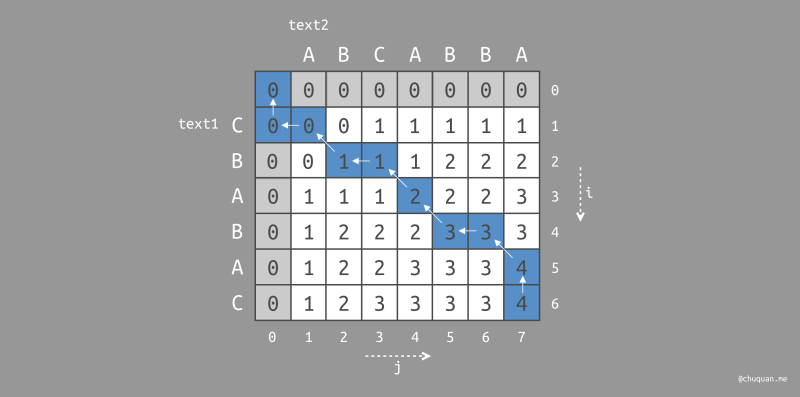
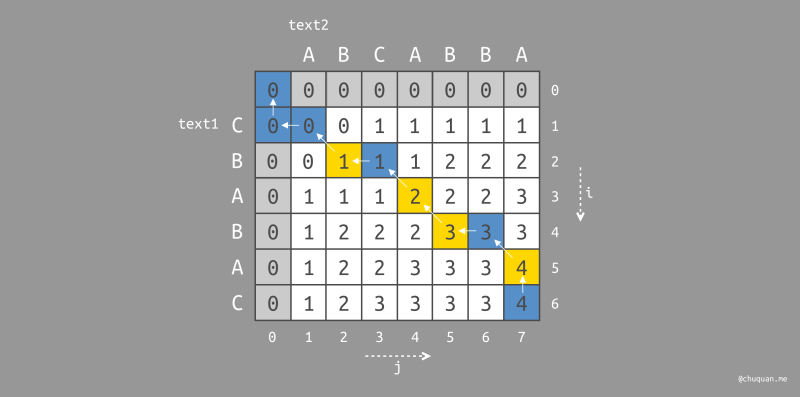
同样,我们对路径中向左上角遍历的起始位置进行染色(黄色),即可得到最长公共子序列
BABA,如下图所示。
最小编辑距离
事实上,在特定设定下,最长公共子序列问题可以等价为 最小编辑距离(Minimum Edit Distance,也称 Levenshtein) 问题。
具体设定为:在最小编辑距离问题中,如果编辑操作只有 删除 和 插入,没有 替换 操作,且每个操作的代价是 1,那么从字符串 A 转换成字符串 B 的最小编辑距离就可以转换成如下公式。
\[ med(A, B) = length(A) + length(B) - 2 * lcs(A, B) \]
以上述 text1 = CBABAC,text2 = ABCABBA
为例,寻找最长公共子序列问题,我们可以视为将 text2 转换成
text1 的最小编辑距离问题。
此时,我们可以将向左遍历的起始位置染成红色,将向上遍历的起始位置染成绿色,如下所示是分别对
CABA 和 BABA 遍历路径的染色图。
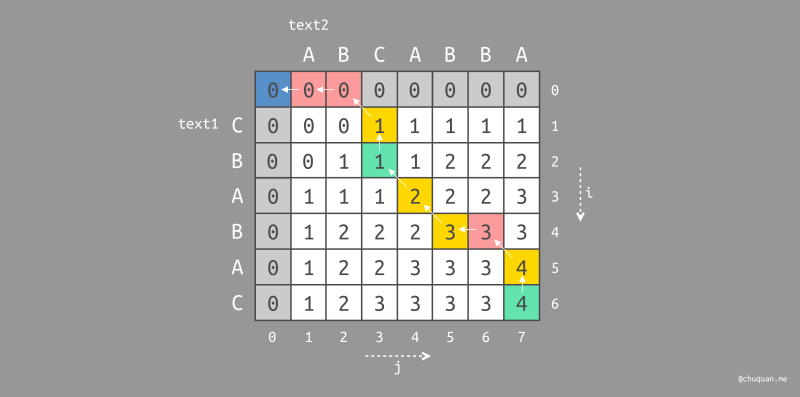
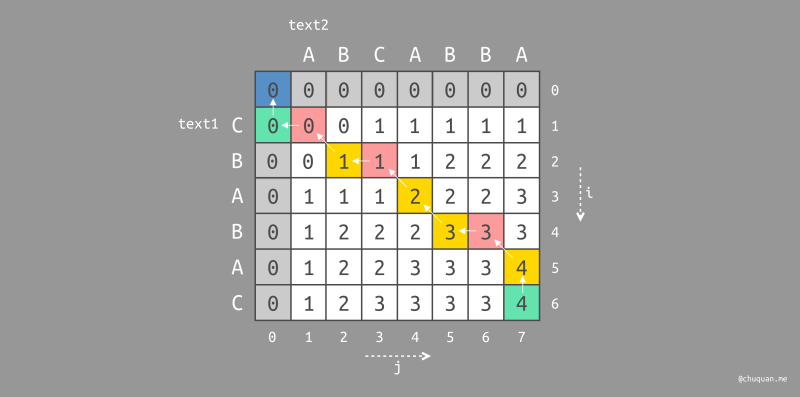
这里,我们对已经染色的路径进行编辑规则的定义,如下:
- 被染成红色的位置,表示在路径中删除原始字符串对应的字符
- 被染成绿色的位置,表示在路径中插入目标字符串对应的字符
- 被染成黄色的位置,表示不进行任何编辑编辑操作
此时,我们就可以得到最小编辑距离的实际操作步骤,即 最短编辑脚本(Shortest Edit Script,SES),如下所示。
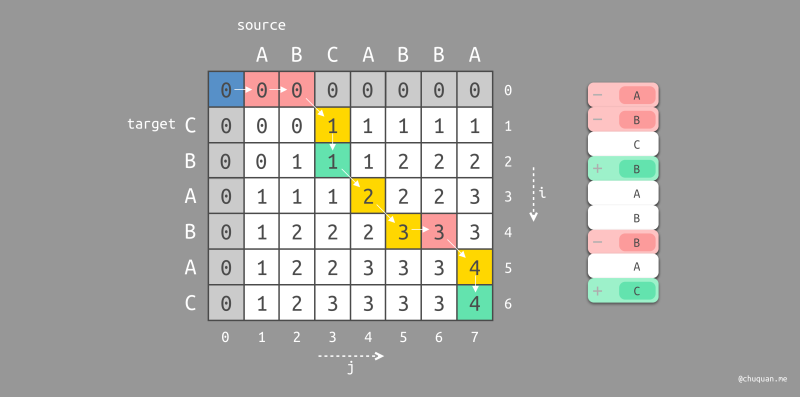
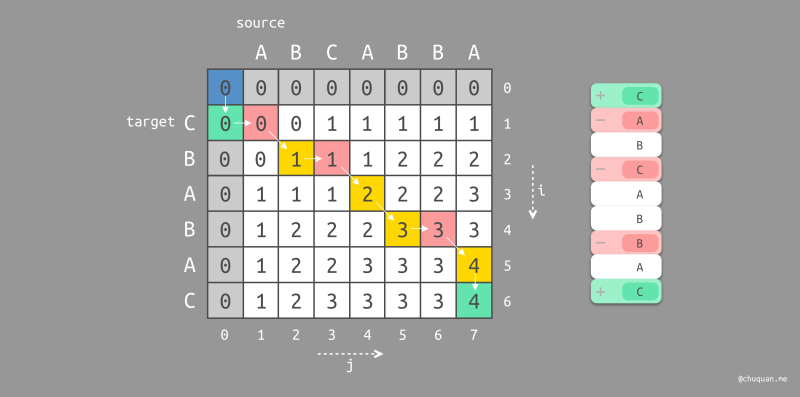
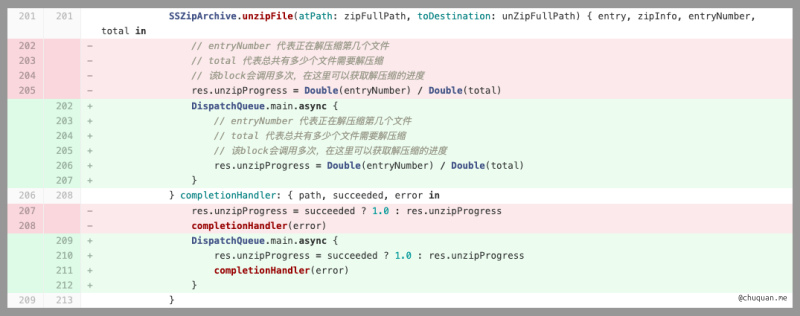
上面两图的右半部分是两个符合预期的最短编辑脚本。然而,在实际过程中,对某一个原始文本进行编辑得到另一个目标文本,可能会存在非常多的最短编辑脚本。此时我们该如何选择?根据实际经验,我们认为先删除旧内容,后插入新内容,具有更直观的体验。比如:Code Review 的差异比较也都是按照先删除后插入的方式进行展示,如下所示。因此,上述第一种最短编辑脚本更加直观,符合预期。
Myers 差分算法
1986 年 Eugene W.Myers 发表了一篇论文《An O(ND) Difference Algorithm and Its Variations》,提出一种基于广度优先搜索和贪心策略的算法,优化了最短编辑路径问题。该算法在求解大规模字符串编辑距离问题时比传统的动态规划更加有效。
下面,我们以 source = ABCABBA
为原始字符串,target = CBAABAC 为目标字符串,基于 Myers
差分算法来查找最短编辑距离和最小编辑脚本。
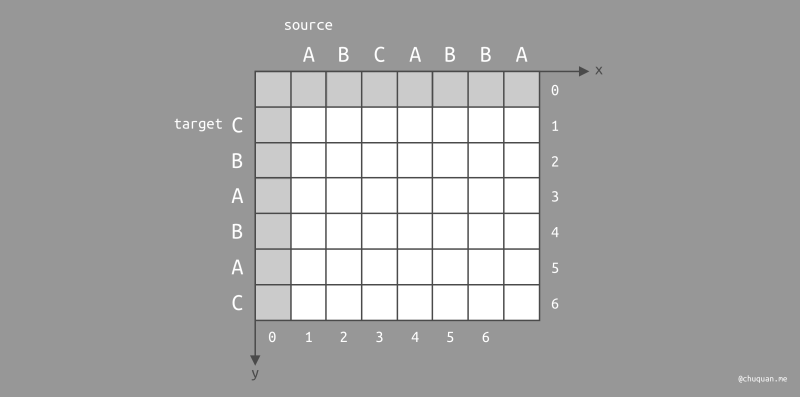
基本定义
与上述算法类似,Myers 差分算法的基本思想仍然是查找一条从左上角至右下角的路径。在路径遍历时,这里有几个基本定义:
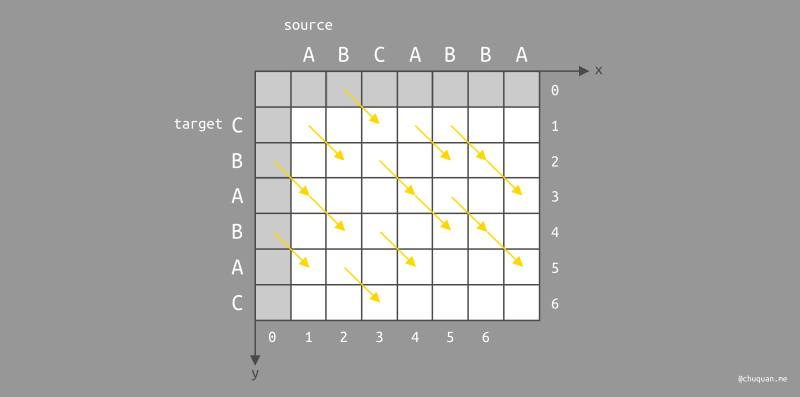
- 遍历的方向:仅支持三个方向,分别是 向右、向下、右下。
- 遍历的步长:对于向右和向下,步长为 1。一次只能移动一格;对于右下,一次可以移动任意长度,前提是移动过程中所有坐标的 x、y 值对应在原始字符串和目标字符串中的对应位置的字符必须相同。下图所示,黄色箭头表示可以允许移动的起始位置和终点位置。
- 遍历的深度:对于向右和向下,每移动一步,深度加 1;对于右下,无论移动步长为多少,深度始终加 0。
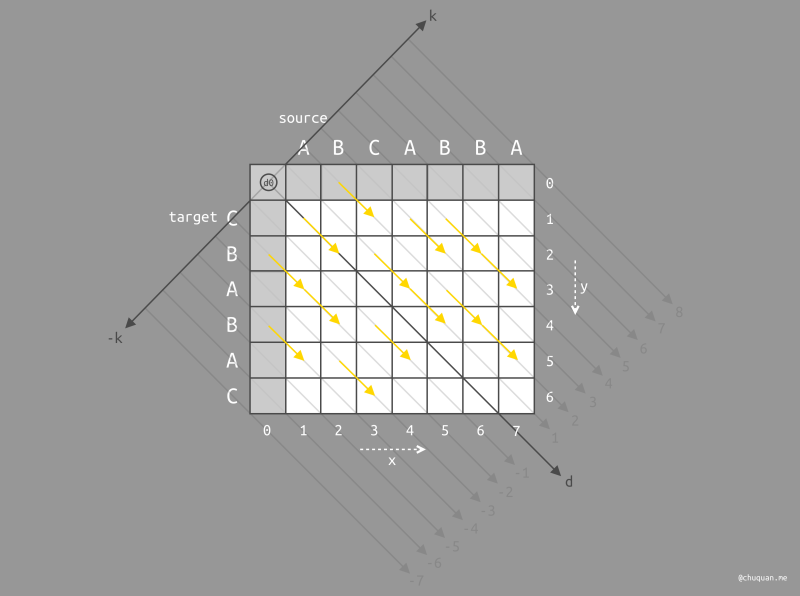
K-D 坐标系
除了对比原始字符串和目标字符串所建立的 X-Y 坐标系外,Myers 还建立了一个 K-D 坐标系,如下图所示。
K 来源于 X 与 Y 的关系式 y = x - k,即偏移量。根据 X 和
K 的值,我们可以计算得到 Y 的值。
D 表示遍历的深度。由于向右或向下移动一步,深度加 1;右下移动一步,深度加 0。因此,D 轴并不是完全垂直于 K 轴,而是类似于等高线,向多方向增长,相同 D 值所连成的线可能是折线,而不一定是直线。

最佳位置
Myers 差分算法是基于贪心策略实现的,对此它定义了一个 最佳位置 的概念,作为贪心的基准值。在 K-D 坐标系中,同一条 K 线上,X 值越大的位置(根据 K 的值可以计算得到 Y 值),则越靠近右下角的终点。
那么如何记录最佳位置?很显然,每一个 K 值需要单独记录各自的最佳位置,因此,需要有一个 Map 来进行存储,其中 Key 是 K 值,Value 则是 X 值。根据 K 和 X,我们可以计算出 Y 值。
算法原理
在了解了算法的基本定义、K-D 坐标系以及最佳位置等概念之后,我们来看一下算法具体原理。
算法整体包含两层循环:
- 外层循环:迭代遍历的深度。在最坏的情况下(删除全部原始字符,掺入全部目标字符),遍历的深度为两个字符的长度之和,因此深度的范围为
[0, M+N)。 - 内层循环:迭代必要的 K 值。对于每一条 K 线,从其上的最佳位置出发,移动深度加 1 后的位置只能在其相邻的两条 K 线上。因此,相同深度的最佳位置所在的 K 线,相邻之间的 K 值差为 2。对应地,内层循环的步长也为 2,并且每一轮遍历,深度加 1,K 的范围也会外扩 2。
下面,我们来图解一下算法的运行过程,以下每张图表示一次完整的内层循环。
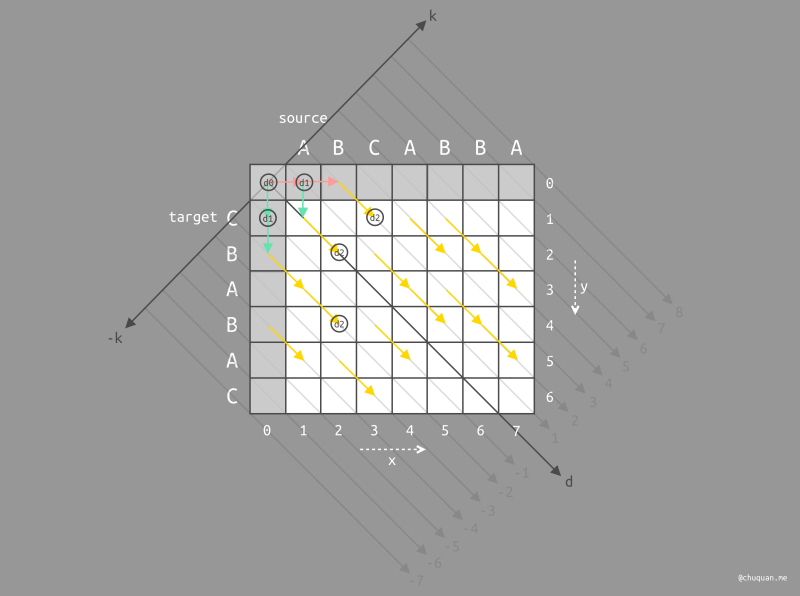
首先,为 k(0) 查找所有深度为 d0
的最佳位置,很显然,只有起点符合,如下图所示。
其次,为 k(-1) 和 k(1) 查找所有深度为
d1 的最佳位置。由于 d1 是基于 d0
宽度优先搜索查找的,而 d0
只有一个,所以由此向两个方向搜索的 K 线只有 k(-1) 和
k(1)。

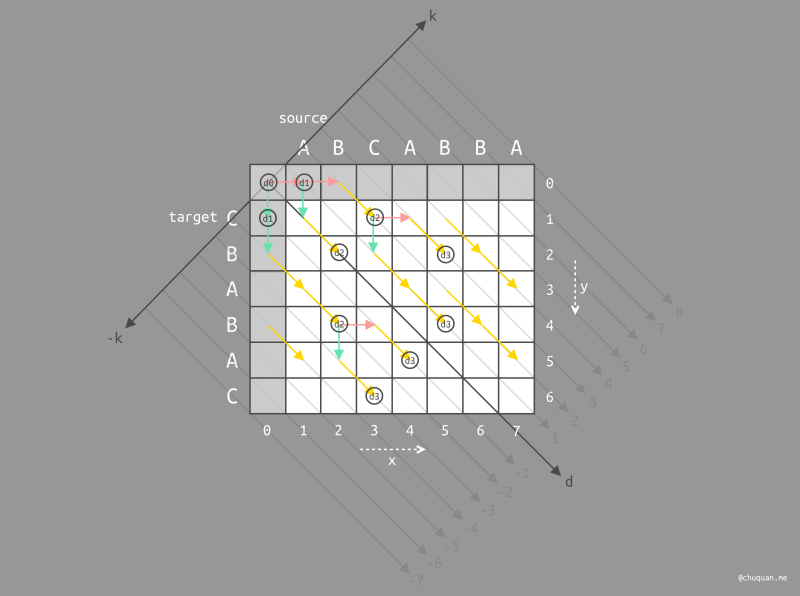
然后,我们继续基于 d1 的各个最佳位置进行宽度优先搜索,为
(k-2)、k(0)、k(2) 查找
d2 的各个最佳位置。由于每一轮内层循环的 K 线数量都会外扩
1,因此,首尾的两条 K 线,只能基于内侧 K
线的上一轮循环最佳位置来查找本轮最佳位置;对于中间的 K 线,它两侧的 K
线都有上一轮的最佳位置,它可以从中选择更优的最佳位置(即 X
值更大的最佳位置)来查找本轮的最佳位置。如下图所示,k(-2)
的最佳位置 d2 只能基于 k(-1) 的最佳位置
d1 来查找得到;k(2) 的最佳位置 d2
只能基于 k(1) 的最佳位置 d1
来查找得到。对于中间的 K 线,这里只有
k(0),它会在左右两边的 K 线中选择一个最佳位置,显然
k(1) 上的 d1 的 X
值更大,因此选择它作为搜索的起点。
从图中,我们还可以看到,当到达深度加 1
的位置后,算法还会进一步判断是否可以向右下移动,因为右下移动时,深度不会增加。此时,我们发现这几个位置都能沿着黄色的线移动,于是
d2 就到达了图中所示的位置。
接着,为
k(-3)、k(-1)、k(1)、k(3)
查找 d3 的各个最佳位置。注意,这里我们看一下
k(-1) 的处理,此时它两侧 k(-2) 和
k(0) 的最佳位置的 X 值相同。此时,我们选择基于
k(-2) 右移,很明显,这样必然会比基于 k(0)
下移能找到 X 值更大的位置。
然后,为
k(-4)、k(-2)、k(0)、k(2)、k(4)
查找 d4 的各个最佳位置。注意,此时会存在部分 K
线的最佳位置不包含 X-Y 坐标系中真实存在的位置,比如 k(-4)
的最佳位置。
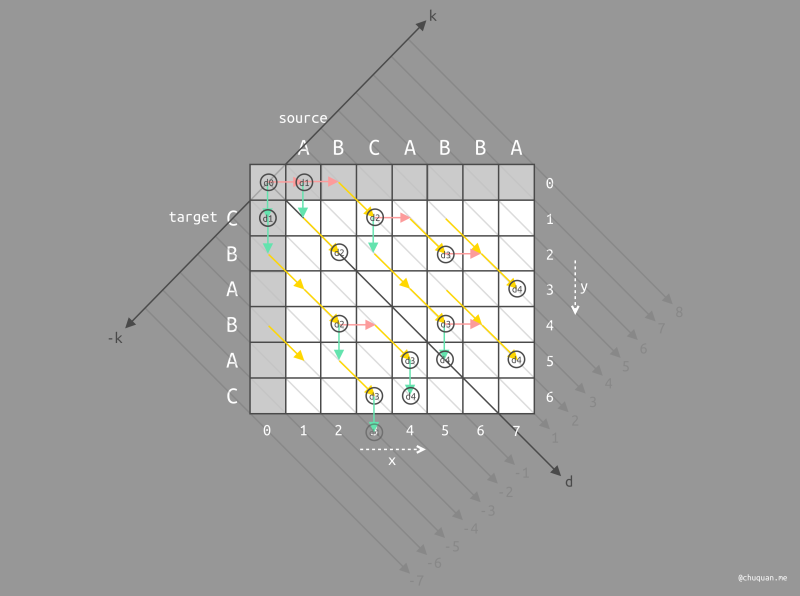
最后,我们在为
k(-5)、k(-3)、k(-1)、k(1)、k(3)、k(5)
查找最佳位置时,发现其中一条 K
线的最佳位置已经到达终点,那么此时我们已经找到了最短编辑距离,那么可以结束遍历。
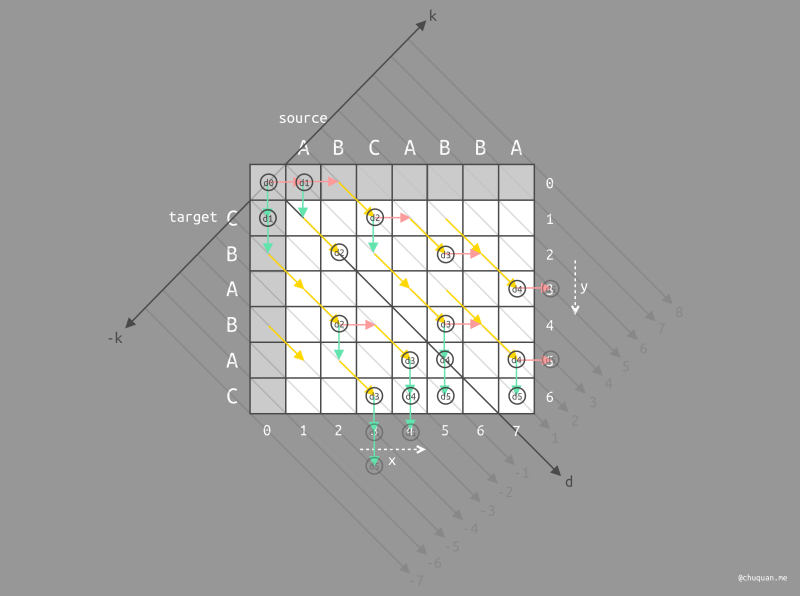
在上述过程中,Myers 算法使用一个 Map 记录每条 K 线的最佳位置,其中 Key 为 K 值,Value 为最佳位置。当对同一条 K 线多次更新最佳位置时,Map 只会记录最新的最佳位置。为了便于复现完整的编辑路径,Myers 算法还使用一个 Map 用于记录每个深度的所有最佳位置,其中 Key 为深度值 D,Value 是一个子 Map,记录了该深度时各个 K 线的最佳位置。通过回溯这个包含全部最佳位置的 Map,我们可以重建遍历路径,如下图所示。
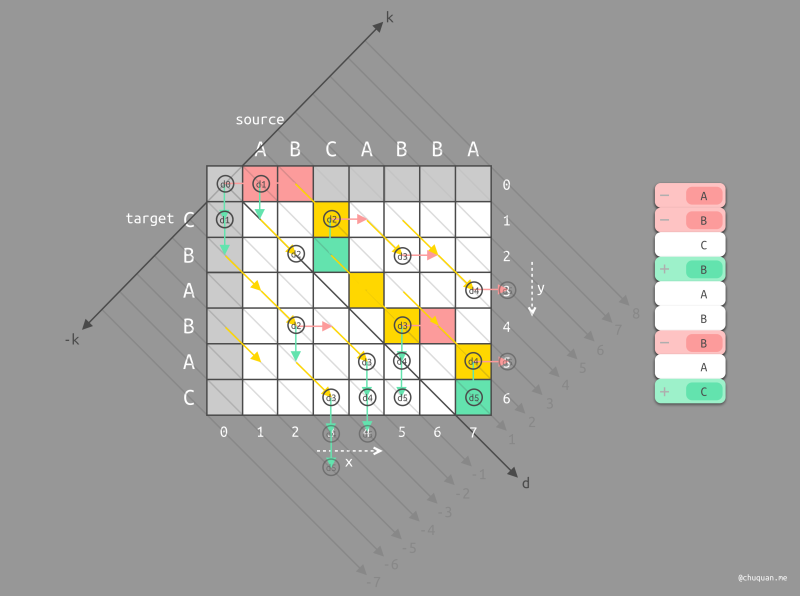
算法实现
下面,我们使用代码来实现一下 Myers 算法。
1 | # ruby |
总结
传统动态规划的时间复杂度为 O(mn),空间复杂度为
O(mn),其中 m 和 n
分别是两个字符串的长度;Myers 算法的时间复杂度为
O((m+n)D),D
是最小编辑距离,当最短编辑距离相对较小时,Myers
算法的时间效率是优于传统动态规划的,Myers 算法的空间复杂度为
O(m+n)。因此,当面对大规模且较为相似的字符串比较任务时,Myers
算法相比动态规划更具优势。
后续,我们将阅读一些开源软件或框架,来学习一下 Myers 差分算法在其中的应用。
参考
- Visualizing Diffs
- git生成diff原理:Myers差分算法
- 一种diff算法:Myers
- The Myers diff algorithm: part 1
- The Myers diff algorithm: part 2
- The Myers diff algorithm: part 3
- Myers diff in linear space: theory
- Myers diff in linear space: implementation
- An O(ND) Difference Algorithm and Its Variations. Eugene W.Myers.
- Diff应用:从LCS 到UICollectionView
- Myers差分算法的理解、实现、可视化
- Myers‘Diff之贪婪算法
- pkg diff