
基于 LLVM 自制编译器(9)——调试信息
概述
通过 8 章的教程,我们实现了一门支持函数和变量的编程语言。那么,如果代码运行或编译出错时,我们该如何调试程序呢?
本质上,源码调试是基于 格式化数据 实现的,格式化数据可以辅助调试器实现二进制和机器状态转换至程序员编写的源码。在 LLVM 中,我们通常使用一种称为 DWARF 的格式。DWARF 是一种紧凑的编码,可以表示类型、源码位置、变量位置。
本章,我们将介绍如何基于 DWARF 为 Kaleidoscope 实现调试能力。
目前我们无法通过 JIT 进行调试,因此我们需要将我们的程序编译为小型且独立的东西。作为其中的一部分,我们将对语言的运行和程序的编译方式进行一些修改。 这意味着我们将拥有一个源文件,其中包含一个用 Kaleidoscope 编写的简单程序,而不是交互式 JIT。它确实涉及一个限制,即我们一次只能有一个“顶级”命令,以减少必要的更改数量。
1 | def fib(x) |
实现难点
编译器支持调试信息的主要实现难点在于 已优化的代码。
首先,编译器代码优化使得保留源码位置更加困难。在 LLVM IR 中,我们为每个 IR 级指令保留源码位置。优化通道同样也会保存新创建指令的源码位置,但合并的指令只能保留一个位置,这可能会导致在单步执行优化程序时出现跳转。
其次,部分优化通道可能会移动变量的位置,从而导致变量难以追溯。
源码位置
从实现难点中我们可以看出,实现调试的关键在于
源码位置。因此,我们定义了 SourceLocation
数据结构,用于存储源码位置信息,同时使用两个全局变量 CurLoc
和 LexLoc 分别存储词法分析时的当前位置信息和 token
位置信息。
1 | struct SourceLocation { |
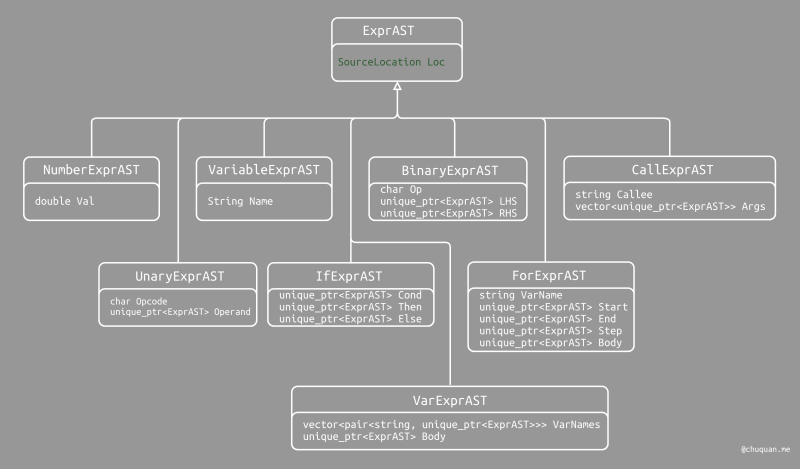
为了让 AST 支持存储源码位置,我们对 ExprAST 扩展了
Loc
字段,用于保存对应表达式的位置信息,如下所示。同时,ExprAST
提供了几个便利方法,用于读取行和列的信息。
1 | /// ExprAST - Base class for all expression nodes. |
那么源码位置在哪里读取呢?很显然,在词法分析阶段进行读取。因此,我们实现了一个新的词法分析输入器
advance(),如下所示。
1 | static int advance() { |
同时,我们将词法分析器的输入器 getchar() 替换成
advance(),从而实现了字符、位置等信息的读取。
调试信息
接下来,我们定义一个 DebugInfo
结构用于表示调试信息,其主要包含三个字段:
TheCU:DICompileUnit *类型,用于表示一个编译单元。在编译过程中,一个源文件对应一个编译单元。DblTy:DIType *类型,用于表示一个数据类型。由于 Kaleidoscope 只包含一种类型double,因此这里只定义一个字段。LexicalBlocks:vector<DIScope *>类型,用于表示一个作用域栈,栈顶的作用域表示当前作用域。
1 | struct DebugInfo { |
为了确保每条指令都能获得正确的源码位置,当处于新的源码位置时,我们必须通知
IRBuilder。为此,我们通过 DebugInfo
提供一个辅助方法 emitLocation。
DWARF 生成设置
对于支持 LLVM IR,我们通过 IRBuilder
来实现代码生成。对于支持调试信息,我们通过 DIBuilder 来构建
调试元数据。
这里,我们使用 DIBuilder 来构建所有的 IR 级别描述。基于
DIBuilder 构建 LLVM IR
的前提是必须构建一个模块。因此,我们在构建模块之后立即构建
DIBuilder,并将其作为全局静态变量,以便于使用,如下所示。
1 | static std::unique_ptr<DIBuilder> DBuilder; |
主流程
上面,我们让词法分析器支持读取位置信息,并且定义了
DebugInfo 类型用于表示调试信息。
下面,我们来修改编译器的主流程。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49int main() {
InitializeNativeTarget();
InitializeNativeTargetAsmPrinter();
InitializeNativeTargetAsmParser();
// Install standard binary operators.
// 1 is lowest precedence.
BinopPrecedence['='] = 2;
BinopPrecedence['<'] = 10;
BinopPrecedence['+'] = 20;
BinopPrecedence['-'] = 20;
BinopPrecedence['*'] = 40; // highest.
// Prime the first token.
getNextToken();
TheJIT = ExitOnErr(KaleidoscopeJIT::Create());
InitializeModule();
// Add the current debug info version into the module.
TheModule->addModuleFlag(Module::Warning, "Debug Info Version",
DEBUG_METADATA_VERSION);
// Darwin only supports dwarf2.
if (Triple(sys::getProcessTriple()).isOSDarwin())
TheModule->addModuleFlag(llvm::Module::Warning, "Dwarf Version", 2);
// Construct the DIBuilder, we do this here because we need the module.
DBuilder = std::make_unique<DIBuilder>(*TheModule);
// Create the compile unit for the module.
// Currently down as "fib.ks" as a filename since we're redirecting stdin
// but we'd like actual source locations.
KSDbgInfo.TheCU = DBuilder->createCompileUnit(
dwarf::DW_LANG_C, DBuilder->createFile("fib.ks", "."),
"Kaleidoscope Compiler", false, "", 0);
// Run the main "interpreter loop" now.
MainLoop();
// Finalize the debug info.
DBuilder->finalize();
// Print out all of the generated code.
TheModule->print(errs(), nullptr);
return 0;
}DIBuilder。然后通过 DIBuilder
构造一个编译单元,并存储在全局变量 KSDgbInfo 的
TheCU 字段中。中间开始执行代码的编译。最后,通过调用
DBuilder->finalize() 确定调试信息。
这里有几点值得注意:
- 首先,当我们为一种 Kaleidoscope 语言生成编译单元时,我们使用了 C 语言常量。这是因为调试器不一定能理解它无法识别的语言的调用或 ABI,相对而言,我们在 LLVM 代码生成中使用 C ABI,这是比较准确的。这能够确保我们可以真正从调试器调用函数并让它们执行。
- 其次,我们在
createCompileUnit调用中看到fib.ks。这里是一个默认的硬编码值,因为我们使用 shell 重定向将源代码输入 Kaleidoscope 编译器。在常规的编译前端中,我们会有一个输入文件名。
在主流程中,MainLoop()
包含了编译器的核心逻辑。接下来,我们来看看其中函数的定义与调用是如何支持调试信息的。
函数
上面,我们介绍了编译单元和源码位置。现在,我们为函数定义支持调试信息中。如下所示,我们对
FunctionAST::codegen() 进行了改造,使其支持插入调试信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66Function *FunctionAST::codegen() {
// Transfer ownership of the prototype to the FunctionProtos map, but keep a
// reference to it for use below.
auto &P = *Proto;
FunctionProtos[Proto->getName()] = std::move(Proto);
Function *TheFunction = getFunction(P.getName());
if (!TheFunction)
return nullptr;
// If this is an operator, install it.
if (P.isBinaryOp())
BinopPrecedence[P.getOperatorName()] = P.getBinaryPrecedence();
// Create a new basic block to start insertion into.
BasicBlock *BB = BasicBlock::Create(*TheContext, "entry", TheFunction);
Builder->SetInsertPoint(BB);
// Create a subprogram DIE for this function.
DIFile *Unit = DBuilder->createFile(KSDbgInfo.TheCU->getFilename(),
KSDbgInfo.TheCU->getDirectory());
DIScope *FContext = Unit;
unsigned LineNo = P.getLine();
unsigned ScopeLine = LineNo;
DISubprogram *SP = DBuilder->createFunction(
FContext,
P.getName(),
StringRef(),
Unit,
LineNo,
CreateFunctionType(TheFunction->arg_size(), Unit),
ScopeLine,
DINode::FlagPrototyped,
DISubprogram::SPFlagDefinition
);
TheFunction->setSubprogram(SP);
// Push the current scope.
KSDbgInfo.LexicalBlocks.push_back(SP);
// Unset the location for the prologue emission (leading instructions with no
// location in a function are considered part of the prologue and the debugger
// will run past them when breaking on a function)
KSDbgInfo.emitLocation(nullptr);
// Record the function arguments in the NamedValues map.
NamedValues.clear();
unsigned ArgIdx = 0;
for (auto &Arg : TheFunction->args()) {
// Create an alloca for this variable.
AllocaInst *Alloca = CreateEntryBlockAlloca(TheFunction, Arg.getName());
// Create a debug descriptor for the variable.
DILocalVariable *D = DBuilder->createParameterVariable(
SP, Arg.getName(), ++ArgIdx, Unit, LineNo, KSDbgInfo.getDoubleTy(),
true);
DBuilder->insertDeclare(Alloca, D, DBuilder->createExpression(),
DILocation::get(SP->getContext(), LineNo, 0, SP),
Builder->GetInsertBlock());
// Store the initial value into the alloca.
Builder->CreateStore(&Arg, Alloca);
// Add arguments to variable symbol table.
NamedValues[std::string(Arg.getName())] = Alloca;
}FunctionAST::codegen()
中关于调试信息相关的逻辑如下
- 基于编译单元
KSDbgInfo.TheCU,调用DBuilder->createFile方法,构造DIFile调试文件。 - 根据函数行号、函数名、函数作用域、
DIFile等信息,调用DBuilder->createFunction方法,构造DISubprogram调试函数,其包含了对函数多有元数据的引用,可用于辅助支持调试。 - 开始解析函数内容。由于函数支持嵌套作用域。因此,将当前的函数作用域向
KSDbgInfo.LexicalBlocks作用域栈压栈。 - 开始解析函数参数。为了避免为函数原型生成行信息,我们调用
KSDbgInfo.emitLocation(nullptr)对源码位置进行复位。 - 函数参数解析过程,对于每一个参数,调用
DBuilder->createParameterVariable方法,构造DILocalVariable调试变量。基于调试变量,调用DBuilder->insertDeclare方法(lvm.dbg.declare),声明引用一个alloca指令分配的变量,并设置源码位置。 - 结束解析函数参数,开始解析函数体。我们调用
KSDbgInfo.emitLocation(Body.get())对源码位置进行设置。 - 结束解析函数内容。将当前作用域从
KSDbgInfo.LexicalBlocks作用域栈中出栈。
注意,并不是所有代码都需要包含行信息。在
FunctionAST::codegen() 方法中,我们专门通过
KSDbgInfo.emitLocation(nullptr)
避免为函数原型生成行信息。
AOT 编译模式
之前,我们实现的编译器始终是基于 JIT 编译模式,现在,我们实现的编译器将基于 AOT 编译模式。对此,我们在源码中删除交互式输入的相关逻辑,如下所示。
1 | int main() { |
测试
最后,我们可以通过以下命令行将 Kaleidoscope
代码编译为可执行程序。然后,输入 Kaleidoscope 源码文件,生成 LLRVM
IR,其中包含了 DWARF 调试信息。 1
$ Kaleidoscope-Ch9 < fib.ks
总结
本文,我们对 Kaleidoscope 进行了改造,使其能够支持 DWARF 调试信息。DWARF 调试信息作用非常大,可以辅助我们进行代码调试,后续有机会,我们将继续深入了解一下 DWARF。