
编译原理工具系列(2)——yacc
前一篇文章我们介绍了词法分析器生成器 lex,本文我们来介绍语法/语义分析器生成器 yacc。
在编译流程中,词法分析器会扫描代码文件,并将其 token 化。语法/语义分析器则会扫描 token 化后的内容,从而建立语法树,生成语义信息。
下面,我们简单介绍一下 yacc 的工作原理和基本用法。
工作原理
下图所示为 lex 和 yacc 协同工作的示意图。
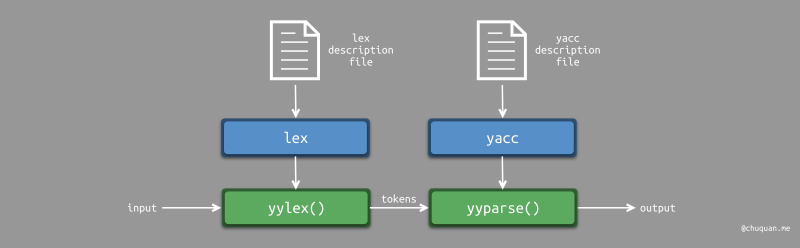
lex 和 yacc 分别使用各自的描述文件生成词法分析器 yylex()
和语法/语义分析器 yyparse()。
yyparse() 自身并不进行词法分析,而是调用
yylex() 进行词法分析。yylex() 返回一个 token
号,表示 token 的类型。token 值则存储在 yylval
变量中。比如:token 的类型为 算术运算符,token 的值为
+。yyparse() 则通过读取
yylex() 的返回值以及 yylval 变量分别获取 token
类型和 token 值。
yyparse() 函数的返回值有两种:
- 当返回值为 0 时,表示解析正确
- 当返回值为 1 时,表示解析错误
描述文件
yacc 描述文件的基本结构与 lex 基本一致,如下所示: 1
2
3
4
5
6
7
8
9定义
%%
规则
%%
代码
描述文件使用 %%
对不同的部分进行分隔,其主要包含三部分内容,分别是:
- 定义(Definitions):可选
- 规则(Rules):必选
- 代码(Codes):可选
定义
定义部分包含三种类型的定义,分别是:
- token 定义
- 优先级与关联性定义
- 变量与函数定义:用于后续的语法分析
token 定义
词法分析器会将所有的字符识别成一个个的 token,语法分析器则会将 token 进行分类处理。因此两者之间必须统一 token 的类型。通常,token 的类型会放在 yacc 描述文件中定义。
token 类型使用 %token 指令进行定义,其一般格式如下所示:
1
%token name1 name2 name3 ...
1
%token INTEGER
yacc 会将 %token 指令转换成 C 语言宏定义
#define。默认,yacc 内部宏定义占用了 0-256
宏定义常量值,因此,%token 命令转换后的宏定义常量值会从 257
开始,依次累加。
优先级与关联性定义
语法分析器分析包含
+、-、*、/
等算术运算符的表达式时,必须根据优先级和关联性来进行分析。
- 对于优先级,
*、/运算符的优先级高于+、-。 - 对于关联性,当一个表达式中包含多个相同优先级操作符,语法分析器必须根据关联性来决定左关联(Left Associative)还是右关联(Right Associative)。比如:对于 C 语言,采用左关联;对于 FORTRAN,采用右关联。
1 | A - B - C |
关于优先级和关联性的定义,yacc 提供了下几个指令:
%left:表示左关联。先定义的优先级低于后定义的优先级。%right:表示右关联。先定义的优先级高于后定义的优先级。%nonassoc:表示无关联。
如下所示为一个简单的算术表达式的优先级和关联性定义。由于
= 为右关联,所以 A = B = C 等同于
A = (B = C)。+、- 比
*、/、% 后定义,所以优先级更低。
1
2
3%right '='
%left '+' '-'
%left '*' '/' '%'
变量与函数定义
定义部分还可以定义基于 C 语言的变量与函数,后续的操作均可以引用。yacc
约定使用 %{ 和 %} 进行定义,如下所示:
1
2
3
4%{
int i, j, k;
static float x = 1.0;
%}
规则
规则部分定义了一系列的 语法翻译规则,每一条语法翻译规则可以分为两部分:标识符 和 定义。
- 标识符:一个非终结符。对应文法产生式的左部。
- 定义:一个或多个终结符或非终结符。对应文法产生式的右部。
- 定义中的每个终结符或非终结符,可选地支持定义一个 语义动作(Sematic Action),即终结符或非终结符匹配时要执行的 C 代码,用于进行语义分析。
语法翻译规则的基本格式如下所示: 1
2
3
4
5
6
7
8// 一个标识符包含一个定义
identifier: definition
// 一个标识符包含多个定义
identifier: definition
| definition
| ...
;
如下所示,为一个算术运算的语法翻译规则。 1
2
3
4
5
6
7intexp : '(' intexp ')' { $$ = $2; }
| intexp '+' intexp { $$ = $1 + $3; }
| intexp '-' intexp { $$ = $1 - $3; }
| intexp '*' intexp { $$ = $1 * $3; }
| intexp '/' intexp { $$ = $1 / $3; }
| INTEGER
;
每个语法翻译规则的定义包含一个或多个终结符或非终结符。当定义匹配时,yacc
默认将第一个匹配符号存储在 $1,第二个匹配符号存储在
$2,以此类推。如果符号是一个终结符(token)时,其值来自于
yylex() 所设置的 yylval
变量。当基于定义归约得到标识符时,将匹配的标识符存储在 $$
变量中。
默认,规则部分定义的第一个非终结符为 开始符号(Start
Symbol)。语法分析器最终生成的语法分析树,其根节点就是开始符号。yacc
提供了 %start 指令,允许用户自定义开始符号。
1
%start name
代码
类似于 lex,yacc 的代码部分也是用于定义 C 代码。yacc 会将这部分代码拷贝至语法分析器代码文件的末尾。当然,yacc 也支持为这部分代码生成一个独立的文件,以支持独立编译。对于大型的编译模块,尤其推荐使用这种独立生成的方式。
比如,对于 yylex(),每次识别一个 token
时,yylex() 都会向 yyparse()
返回一个值表示已识别的 token 的类型。显然,yylex() 和
yyparse() 必须统一对于 token 类型的认知。因此 yacc
可以独立生成一个仅包含 token 宏定义的文件。编译时,我们可以使用
-D
选项来指定编译常量所在的文件,包括:#include、#define
等预编译指令。
案例
下面,我们通过 lex 和 yacc,生成一个能分析加法和乘法表达式的程序。
lex 描述文件 test.l 如下: 1
2
3
4
5
6
7
8
9%%
\* { return ('*'); }
\+ { return ('+'); }
\( { return ('('); }
\) { return (')'); }
[0-9]* { yylval = atoi(yytext); return (NUMBER); }
%%
yacc 描述文件 test.y 如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24%{
int yylex();
void yyerror(const char *s);
%}
%token NUMBER
%%
line : expr { printf("Value = %d", $1); }
;
expr : expr '+' term { $$ = $1 + $3; }
| term { $$ = $1; }
;
term : term '*' factor { $$ = $1 * $3; }
| factor
;
factor : '(' expr ')' { $$ = $2; }
| NUMBER { $$ = $1; }
;
%%
通过以下编译命令可以生成一个可执行文件
test,我们运行该可执行程序,可以输入一行代码,包含多个算术操作。在输入结束符
ctrl + D 后,程序会通过语义动作打印计算结果。
1
2
3$ lex input.l
$ yacc input.y
$ cc y.tab.c -ly -ll -o test
总结
本文我们简单介绍了一下 yacc 与 lex 协同工作的分工与原理,重点介绍了一下 yacc 的描述文件的基本组成,最后介绍了一个结合 lex 和 yacc 开发一个小工具的例子。