
Swift 性能优化(2)——协议与泛型的实现
概述
前一篇文章《Swift 性能优化(1)——基本概念》中我们提到了编程语言的派发方式,Swift 支持文中所提到的三种派发方式。其中,函数表派发是 Swift OOP 的底层支持,那么,Swift POP 以及泛型编程底层又是如何实现的呢?
本文,我们就来简单探讨一下协议和泛型的底层实现原理。如果想深入学习协议和泛型的更多细节和原理,建议去学习一下 Swift Intermediate Language 相关的内容。以后要是有时间,我也想去学习了解一下 SIL。
协议类型 Protocol Type
首先我们举一个例子来看一下 OOP 是如何实现多态的。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Drawable { func draw() }
class Point : Drawable {
var x, y:Double
func draw() { ... }
}
class Line : Drawable {
var x1, y1, x2, y2:Double
func draw() { ... }
}
let point = Point(x: 0, y: 0)
let line = Line(x1: 0, y1: 0, x2: 1, y2: 1)
var drawables: [Drawable] = [point, line]
for d in drawables {
d.draw()
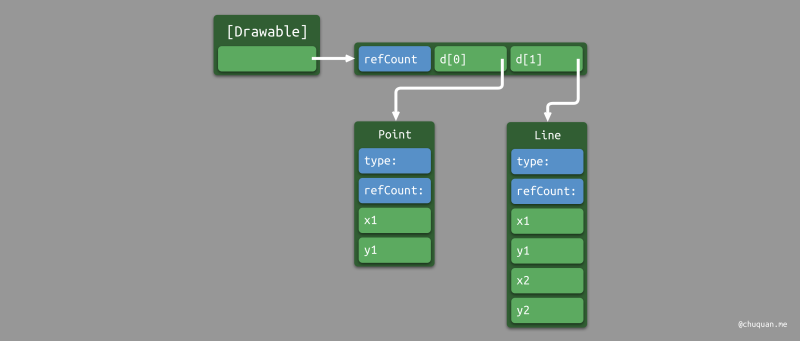
}drawables 是一个元素类型为
Drawable 的数组,由于 class 关键字标记了
Drawable 及其子类 Point、Line
都是引用类型,因此 drawables
的内存布局是固定的,数组里的每一个元素都是一个指针。如下图所示。
接下来,我们再来看 OOP 是如何通过 virtual table
来实现动态派发的。如下图所示
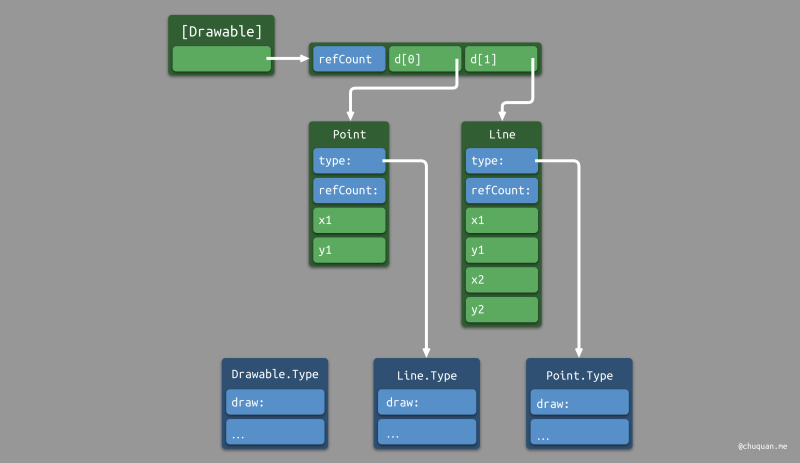
运行时执行 d.draw(),会根据 d
所指向的对象的 type
字段索引到该类型所对应的函数表,最终调用正确的方法。
下面我们举一个例子看一下 POP 是如何实现多态的。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25protocol Drawable { func draw() }
struct Point : Drawable {
var x, y: Double
func draw() { ... }
}
struct Line : Drawable {
var x1, y1, x2, y2: Double
func draw() { ... }
}
class SharedLine: Drawable {
var x1, y1, x2, y2: Double
func draw() { ... }
}
let point = Point(x: 0, y: 0)
let line = Line(x1: 0, y1: 0, x2: 1, y2: 1)
let sharedLine = SharedLine(x1: 0, y1: 0, x2: 1, y2: 1)
var drawables: [Drawable] = [point, line, sharedLine]
for d in drawables {
d.draw()
}Point 和 Line 都是值类型的
struct,只有 SharedLine 是引用类型的
class,并且 Drawable 不再是一个基类,而是一个
协议类型(Protocol Type)。
那么此时,变量 drawables
的内存布局是怎样呢?毕竟,运行时 d
可能是遵循协议的任意类型,类型不同,内存大小也会不同。
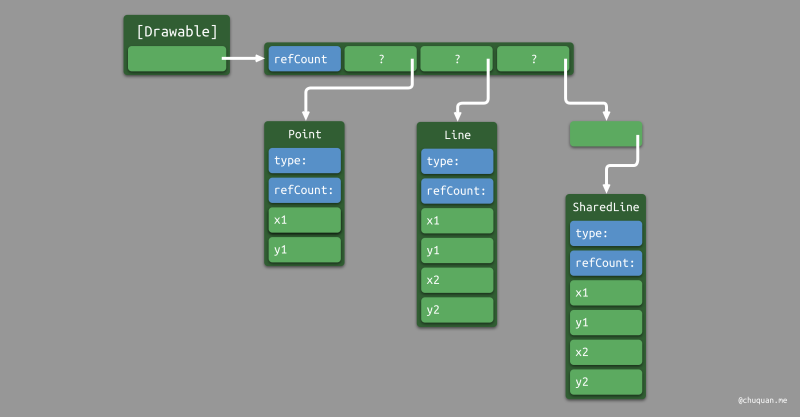
事实上,在这种情况下,变量 drawables
中存储的元素是一种特殊的数据类型:Existential
Container。
Existential Container
Existential Container 是编译器生成的一种特殊的数据类型,用于管理遵守了相同协议的协议类型。因为这些数据类型的内存空间尺寸不同,使用 Extential Container 进行管理可以实现存储一致性。
我们在上述代码的基础上执行下面的示例代码。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20let point = Point(x: 0, y: 0)
let line = Line(x1: 0, y1: 0, x2: 1, y2: 1)
let sharedLine = SharedLine(x1: 0, y1: 0, x2: 1, y2: 1)
print("\(MemoryLayout.size(ofValue: point))")
print("\(MemoryLayout.size(ofValue: line))")
print("\(MemoryLayout.size(ofValue: sharedLine))")
var drawables: [Drawable] = [point, line, sharedLine]
for d in drawables {
print("\(MemoryLayout.size(ofValue: d))")
}
// 原始类型的内存大小,单位:字节
16
32
8
// 协议类型的内存大小,单位:字节
40
40
40
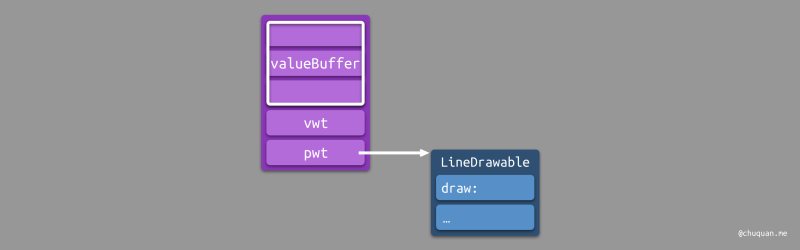
由于本机内存对齐是 8 字节,可见 Extension Container
类型占据 5 个内存单元(也称
词,Word)。其结构如下图所示:

- 3 个词作为 Value Buffer。
- 1 个词作为 Value Witness Table 的索引。
- 1 个词作为 Protocol Witness Table 的索引。
下面,我们依次进行介绍。
Value Buffer
Value Buffer 占据 3 个词,存储的可能是值,也可能是指针。对于 Small Value(存储空间小于等于 Value Buffer),可以直接内联存储在 Value Buffer 中。对于 Large Value(存储空间大于 Value Buffer),则会在堆区分配内存进行存储,Value Buffer 只存储对应的指针。如下图所示。

Value Witness Table
由于协议类型的具体类型不同,其内存布局也不同,Value Witness Table 则是对协议类型的生命周期进行专项管理,从而处理具体类型的初始化、拷贝、销毁。如下图所示:
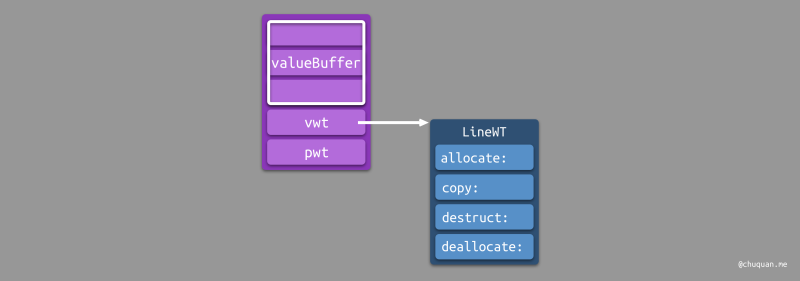
Protocol Witness Table
Value Witness Table 管理协议类型的生命周期,Protocol Witness Table 则管理协议类型的方法调用。
在 OOP 中,基于继承关系的多态是通过 Virtual Table 实现的;在 POP 中,没有继承关系,因为无法使用 Virtual Table 实现基于协议的多态,取而代之的是 Protocol Witness Table。
注:关于 Virtual Table 和 Protocol Witness Table 的区别,我的理解是:
它们都是一个记录函数地址的列表(即函数表),只是它们的生成方式是不同的。
对于 Virtual Table,在编译时,子类的函数表是通过对基类函数表进行拷贝、覆写、插入等操作生成的。
对于 Protocol Witness Table,在编译时,函数表是通过检查具体类型对协议的实现,直接生成的。
协议类型存储属性优化
由上述 Value Buffer 相关内容可知,协议类型的存储分两种情况
- 对于 Small Value,直接内联存储在 Existential Container 的 Value Buffer 中;
- 对于 Large Value,通过堆区分配进行存储,使用 Existential Containter 的 Value Buffer 进行索引。
那么,协议类型的存储属性是如何拷贝的呢?事实上,对于 Small Value,就是直接拷贝 Existential Container,值也内联在其中。但是,对于 Large Value,Swift 采用了 Indirect Storage With Copy-On-Write 技术进行了优化。
这种技术可以提高内存指针利用率,降低堆区内存消耗,从而实现性能提升。该技术的原理是:拷贝时仅仅拷贝 Extension Container,当修改值时,先检测引用计数,如果引用计数大于 1,则开辟新的堆区内存。其实现伪代码如下所示:
1 | class LineStorage { |
泛型类型 Generic Type
下面,我们来讨论泛型的实现。首先来看一个例子。 1
2
3
4
5
6
7
8
9
10func foo<T: Drawable>(local: T) {
bar(local)
}
func bar<T: Drawable>(local: T) {
}
let point = Point()
foo(point)
上述代码中,泛型方法的调用过程大概如下: 1
2
3
4// foo 方法执行时,Swift 将泛型 T 绑定为具体类型。示例中是 Point
foo(point) --> foo<T = Point>(point)
// 调用内部 bar 方法时,Swift 会使用已绑定的变量类型 Point 进一步绑定到 bar 方法的泛型 T 上。
bar(local) --> bar<T = Point>(local)
相比协议类型而言,泛型类型在调用时总是能确定类型,因此无需使用 Existential Container。在调用泛型方法时,只需要将 Value Witness Table/Protocol Witness Table 作为额外参数进行传递。
注:根据方法调用时数据类型是否确定可以将多态分为:静态多态(Static Polymorphism)和 动态多态(Dynamic Polymorphism)。
在泛型类型调用方法时, Swift 会将泛型绑定为具体的类型。因此泛型实现的是静态多态。
在协议类型调用方法时,类型是 Existential Container,需要在方法内部进一步根据 pwt 进行方法索引。因此协议实现的是动态多态。
泛型特化
我们以一个例子来说明编译器对于泛型的一种优化技术:泛型特化。
1
2
3
4
5
6
7func min<T: Comparable>(x: T, y: T) -> T {
return y < x ? y : x
}
let a: Int = 1
let b: Int = 2
min(a, b)min() 方法时的类型。此时,编译器就会通过泛型特化,进行
类型取代(Type Substitute),生成如下的一个方法:
1
2
3func min<Int>(x: Int, y: Int) -> Int {
return y < x ? y :x
}
全模块优化
泛型特化的前提是编译器在编译期间可以进行类型推导,这就要求在编译时提供类型的上下文。如果调用方和类型是单独编译的,就无法在编译时进行类型推导,因此无法使用泛型特化。为了能够在编译期间提供完整的上下文,我们可以通过 全模块优化(Whole Module Optimization) 编译选项,实现调用方和类型在不同文件时也能进行泛型特化。
全模块优化是用于 Swift 编译器的优化机制。从 Xcode 8 开始默认开启。
总结
本文,我们了解了协议类型和泛型类型对于多态的实现,从中我们也看到了编译器对于 Swift 性能的优化发挥了巨大的作用,如:泛型特化、生成代码实现 Copy-On-Write。
此外,我们了解了关于泛型和协议关于性能优化的启示,能够我们制定技术方案时进行权衡。
参考
- WWDC 2016, Session 416, Understanding Swift Performance.
- LLVM Developer’s Meeting: “Implementing Swift Generics”.
- Swift Intermediate Languages(SIL)
- Protocol Witnesses
- 重新檢視 Swift 的 Protocol (二)
- 重新檢視 Swift 的 Protocol (三)