
iOS 性能监控(1)——CPU、Memory、FPS
前段时间,在公司的 App 中集成了一个性能监视器,效果如下所示。在这个过程中,扒了一些性能监测开源框架的源码,并学习了其中的原理。本文就对此做一些简要的总结。

概述
通常情况下,App 的性能问题并不会导致 App 不可用,但是会潜在地影响用户体验。比如:CPU 占用率过高会导致电量消耗过快,手机发热等问题。为了能够主动、高效地发现性能问题,避免 App 质量进入无人监控的状态,我们需要对 App 的性能进行监控。目前,对 App 的性能监控,主要分为 线下 和 线上 两种监控维度。
线下性能监控
关于线下性能监控,Xcode 内置提供了一个性能分析工具 Instruments。
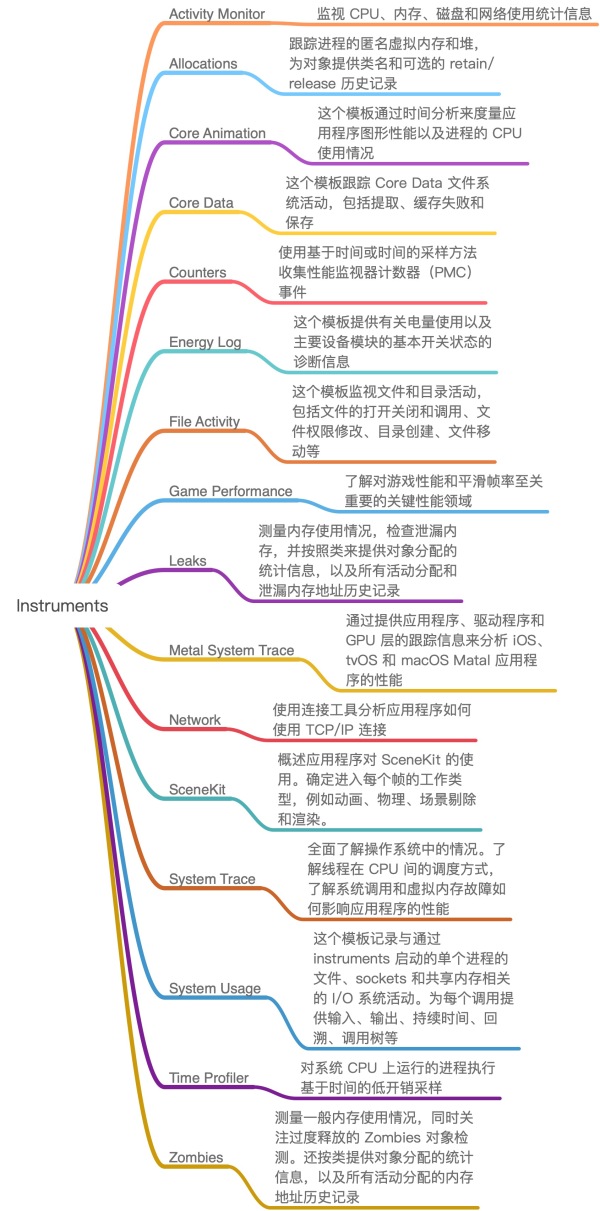
Instruments 集成了非常多的性能检测工具,如:Leaks 可以用来监控内存泄露问题;Energy Log 可以用来监控耗电量。下图所示为 Instruments 中包含的各种性能检测工具。
通常,我们会在提审前使用 Instruments 对 App 进行线下的性能分析。
线上性能监控
线上监控一般需要遵循两个原则:
- 监控代码与业务代码解耦
- 采用性能消耗最小的性能监控方案
线上性能监控,主要集中在对 CPU 使用率、内存、FPS 帧率等方面的监控。下面分别介绍其各自的监控方法及原理。
CPU
CPU 占用率的采集原理其实很简单:App 作为进程运行时会有多个线程,每个线程对 CPU 的使用率不同。各个线程对 CPU 使用率的总和,就是当前 App 对 CPU 的占用率。
相关系统原理
iOS 是基于 Apple Darwin 内核,由 kernel、XNU 和 Runtime 组成,XNU(X is not UNIX) 是 Darwin 的内核,一个混合内核,由 Mach 微内核和 BSD 组成。Mach 内核是轻量级的平台,只能完成操作系统最基本的职责,如:进程和线程、虚拟内存管理、任务调度、进程通信和消息传递机制。其他的工作,如文件操作和设备访问,都是由 BSD 层实现。
事实上,Mach 并不能识别 UNIX 中的所有进程,而是采用一种稍微不同的方式,使用了比进程更轻量级的概念:任务(Task)。经典的 UNIX 采用了自上而下的方式:最基本的对象是进程,然后进一步划分为一个或多个线程;Mach 则采用了自底向上的方式:最基本的单元是线程,一个或多个线程包含在一个任务中。
线程
- 线程定义了 Mach 中最小的执行单元。线程表示的是底层的机器寄存器状态以及各种调度统计数据,其从设计上提供了调度所需要的大量信息。
任务
- 任务是一种容器对象,虚拟内存空间和其他资源都是通过这个容器对象管理的。这些资源包括设备和其他句柄。资源进一步被抽象为端口。因此,资源的共享实际上相当于允许对对应端口进行访问。
严格来说,Mach 的任务并不是hi操作系统中所谓的进程,因为 Mach
作为一个微内核的操作系统,并没有提供“进程”的逻辑,而只提供了最基本的实现。在
BSD 模型中,这两个概念有一对一的简单映射,每个 BSD 进程(即 OS X
进程)都在底层关联了一个 Mach
任务对象。实现这种映射的方法是指定一个透明的指针
bsd_info,Mach 对 bsd_info 完全无知。Mach
将内核也用任务表示(全局范围称为
kernel_task),尽管该任务没有对应的 PID,但可以想象 PID 为
0。
下图所示为权威著作《OS X Internal: A System Approach》中提供的 Mach OS X 中进程子系统组成的概念图。与 Mac OS X 类似,iOS 的线程技术也是基于 Mach 线程技术实现的。

代码实现
上述提到线程表示的是底层的机器寄存器状态以及各种给调度统计数据。再来看
Mach 层中的 thread_basic_info
结构体的定义,其成员信息也证实了这一点。 1
2
3
4
5
6
7
8
9
10struct thread_basic_info {
time_value_t user_time; // 用户运行时长
time_value_t system_time; // 系统运行时长
integer_t cpu_usage; // CPU 使用率
policy_t policy; // 调度策略
integer_t run_state; // 运行状态
integer_t flags; // 各种标记
integer_t suspend_count; // 暂停线程的计数
integer_t sleep_time; // 休眠时间
};cpu_usage 字段的值,就可以得到当前 App 所在进程的 CPU
使用率。
如下所示为 CPU 占用率 的代码实现:
1 | // 获取 CPU 使用率 |
代码中使用 task_threads API 调用获取指定的 task
的线程列表。task_threads 将 target_task
任务中的所有线程保存在 act_list 数组中,数组包含
act_listCnt 个条目。上述源码中,在调用
task_threads API 时,target_task 参数传入的是
mach_task_self(),表示获取当前的 Mach task。
1
2
3
4
5
6kern_return_t task_threads
(
task_t target_task,
thread_act_array_t *act_list,
mach_msg_type_number_t *act_listCnt
);
在获取到线程列表后,代码中使用 thread_info API
调用获取指定线程的线程信息。thread_info 查询
flavor 指定的线程信息,将信息返回到长度为
thread_info_outCnt 字节的 thread_info_out
缓存区中。上述源码,在调用 thread_info API
时,flavor 参数传入的是
THREAD_BASIC_INFO,使用这个类型会返回线程的基本信息,即
thread_basic_info_t 结构体。 1
2
3
4
5
6
7kern_return_t thread_info
(
thread_act_t target_act,
thread_flavor_t flavor,
thread_info_t thread_info_out,
mach_msg_type_number_t *thread_info_outCnt
);
上述源码的最后,使用 vm_deallocate API
以防止出现内存泄露。
使用该方法采集到的 CPU 数据与腾讯的 GT、Instruments 数据接近。事实上,GT 也是采用这种方法采集 CPU 数据。
Memory
通过上述 CPU 占用率监控原理,我们可以联想:内存使用情况是否也可以通过类似的方式获取到呢?答案是肯定的。
相关系统原理
内存是有限且系统共享的资源,一个程序占用越多,系统和其他程序所能用的就越少。程序启动前都需要先加载到内存中,并且在程序运行过程中的数据操作也会占用一定的内存资源。减少内存占用也能同时减少其对 CPU 时间维度上的消耗,从而使不仅使 App 以及整个系统也都能表现的更好。
MacOS 和 iOS 都采用了虚拟内存技术来突破物理内存的大小限制,每个进程都有一段由多个大小相同的页(Page)所构成的逻辑地址空间。处理器和内存管理单元(MMU,Memory Management Unit)维护着由逻辑地址到物理地址的 页面映射表(简称 页表),当程序访问逻辑内存地址时,由 MMU 根据页表将逻辑地址转换为真实的物理地址。在早期的苹果设备中,每个页的大小为 4KB;基于 A7 和 A8 处理器的系统为 64 位程序提供了 16KB 的虚拟内存分页和 4KB 的物理内存分页;在 A9 之后,虚拟内存和物理内存的分页大小都达到了 16KB。
虚拟内存分页(Virtual Page,VP)有两种类型:
- Clean:指能够被系统清理出内存且在需要时能重新加载的数据,包括:
- 内存映射文件
- Frameworks 中的 __DATA_CONST 部分
- 应用的二进制可执行文件
- Dirty:指不能被系统回收的内存占用,包括:
- 所有堆上的对象
- 图片解码缓冲数据
- Framework 中的 __DATA 和 __DATA_DIRTY 部分
由于内存容量和读写寿命的限制,iOS 上没有 Disk Swap 机制,取而代之使用 Compressed Memory 技术。 Disk Swap 是指在 macOS 以及一些其他桌面操作系统中,当内存可用资源紧张时,系统将内存中的内容写入磁盘中的backing store(Swapping out),并且在需要访问时从磁盘中再读入 RAM(Swapping in)。与大多数 UNIX 系统不同的是,macOS 没有预先分配磁盘中的一部分作为 backing store,而是利用引导分区所有可用的磁盘空间。
苹果最初只是公开了从 OS X Mavericks 开始使用 Compressed Memory 技术,但 iOS 系统也从 iOS 7 开始悄悄地使用。
Compressed Memory 技术在内存紧张时能够将最近使用过的内存占用压缩至原有大小的一半以下,并且能够在需要时解压复用。它在节省内存的同时提高了系统的响应速度,其特点可以归结为:
- 减少了不活跃内存占用
- 改善电源效率,通过压缩减少磁盘 IO 带来的损耗
- 压缩/解压非常快,能够尽可能减少 CPU 的时间开销
- 支持多核操作
本质上,Compressed Memory 也是 Dirty Memory。因此,memory footprint = dirty size + compressed size,这也是我们需要并且能够尝试去减少的内存占用。
代码实现
在 /usr/include/mach/task_info.h 中,我们可以看到
mach_task_basic_info 和 task_basic_info
结构体的定义,分别如下所示。事实上,苹果公司已经不建议再使用
task_basic_info 结构体了。 1
2
3
4
5
6
7
8
9
10
11
12#define MACH_TASK_BASIC_INFO 20 /* always 64-bit basic info */
struct mach_task_basic_info {
mach_vm_size_t virtual_size; /* virtual memory size (bytes) */
mach_vm_size_t resident_size; /* resident memory size (bytes) */
mach_vm_size_t resident_size_max; /* maximum resident memory size (bytes) */
time_value_t user_time; /* total user run time for
terminated threads */
time_value_t system_time; /* total system run time for
terminated threads */
policy_t policy; /* default policy for new threads */
integer_t suspend_count; /* suspend count for task */
};1
2
3
4
5
6
7
8
9
10
11
12/* localized structure - cannot be safely passed between tasks of differing sizes */
/* Don't use this, use MACH_TASK_BASIC_INFO instead */
struct task_basic_info {
integer_t suspend_count; /* suspend count for task */
vm_size_t virtual_size; /* virtual memory size (bytes) */
vm_size_t resident_size; /* resident memory size (bytes) */
time_value_t user_time; /* total user run time for
terminated threads */
time_value_t system_time; /* total system run time for
terminated threads */
policy_t policy; /* default policy for new threads */
};
mach_task_basic_info 结构体存储了 Mach task
的内存使用信息,其中 resident_size 是 App
使用的驻留内存大小,virtual_size 是 App
使用的虚拟内存大小。
如下所示为内存使用情况的代码实现: 1
2
3
4
5
6
7
8
9
10
11
12// 当前 app 内存使用量
+ (NSInteger)useMemoryForApp {
struct mach_task_basic_info info;
mach_msg_type_number_t count = MACH_TASK_BASIC_INFO_COUNT;
kern_return_t kr = task_info(mach_task_self(), MACH_TASK_BASIC_INFO, (task_info_t) &info, &count);
if (kr == KERN_SUCCESS) {
return info.resident_size;
} else {
return -1;
}
}
然而,我用 通过此方法获取到的内存信息与 Instruments 中的
Activity Monitor 采集到的内存信息进行比较,发现前者要多出将近
100MB。经过调研发现,苹果使用了上述的 Compressed
Memory,我猜测:resident_size 可能是将 Compressed Memory
解压后所统计到的一个数值。真实的物理内存的值应该是
task_vm_info 结构体中的 pyhs_footprint
成员的值。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31#define TASK_VM_INFO 22
#define TASK_VM_INFO_PURGEABLE 23
struct task_vm_info {
mach_vm_size_t virtual_size; /* virtual memory size (bytes) */
integer_t region_count; /* number of memory regions */
integer_t page_size;
mach_vm_size_t resident_size; /* resident memory size (bytes) */
mach_vm_size_t resident_size_peak; /* peak resident size (bytes) */
mach_vm_size_t device;
mach_vm_size_t device_peak;
mach_vm_size_t internal;
mach_vm_size_t internal_peak;
mach_vm_size_t external;
mach_vm_size_t external_peak;
mach_vm_size_t reusable;
mach_vm_size_t reusable_peak;
mach_vm_size_t purgeable_volatile_pmap;
mach_vm_size_t purgeable_volatile_resident;
mach_vm_size_t purgeable_volatile_virtual;
mach_vm_size_t compressed;
mach_vm_size_t compressed_peak;
mach_vm_size_t compressed_lifetime;
/* added for rev1 */
mach_vm_size_t phys_footprint;
/* added for rev2 */
mach_vm_address_t min_address;
mach_vm_address_t max_address;
};
因此,正确的内存使用情况的代码实现应该如下: 1
2
3
4
5
6
7
8
9
10
11
12// 当前 app 内存使用量
+ (NSInteger)useMemoryForApp {
task_vm_info_data_t vmInfo;
mach_msg_type_number_t count = TASK_VM_INFO_COUNT;
kern_return_t kernelReturn = task_info(mach_task_self(), TASK_VM_INFO, (task_info_t) &vmInfo, &count);
if (kernelReturn == KERN_SUCCESS) {
int64_t memoryUsageInByte = (int64_t) vmInfo.phys_footprint;
return memoryUsageInByte / 1024 / 1024;
} else {
return -1;
}
}
FPS
FPS(Frames Per Second)是指画面每秒传输的帧数。每秒帧数越多,所显示的动画就越流畅,一般只要保持 FPS 在 50-60,App 就会有流畅的体验,反之会感觉到卡顿。
相关系统原理
CADisplayLink
是一个能让我们以和屏幕刷新率相同的频率将内容画到屏幕上的定时器。
一旦 CADisplayLink 以特定的模式注册到
runloop 之后,每当屏幕需要刷新时,runloop
就会调用 CADisplayLink 绑定的 target 上的
selector,此时 target 可以读取到
CADisplayLink
的每次调用的时间戳,用来准备下一帧显示需要的数据。如:一个视频应用使用时间戳来计算下一帧要显示的视频数据。
代码实现
现阶段,常用的 FPS 监控几乎都是基于 CADisplayLink
实现的。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45// swift
final class FPSMonitor: NSObject {
private var timer: Timer?
private var link: CADisplayLink?
private var count: UInt = 0
private var lastTime: TimeInterval = 0
func enableMonitor() {
if link == nil {
link = CADisplayLink(target: self, selector: #selector(fpsInfoCalculate(_:)))
link?.add(to: RunLoop.main, forMode: .common)
} else {
link?.isPaused = false
}
}
func disableMonitor() {
if let link = link {
link.isPaused = true
link.invalidate()
self.link = nil
lastTime = 0
count = 0
}
}
@objc
func fpsInfoCalculate(_ link: CADisplayLink) {
if lastTime == 0 {
lastTime = link.timestamp
return
}
count += 1
let delta = link.timestamp - lastTime
if delta >= 1 {
// 间隔超过 1 秒
lastTime = link.timestamp
let fps = Double(count) / delta
count = 0
let intFps = Int(fps + 0.5)
print("帧率:\(intFps)")
}
}
}CADisplayLink 实现的 FPS
在生产场景中只有指导意义,不能代表真实的 FPS。因为基于
CADisplayLink 实现的 FPS 无法完全检测出当前 Core
Animation 的性能情况,只能检测出当前 RunLoop
的帧率。
参考
- iOS 性能监控 SDK —— Wedjat(华狄特)开发过程的调研和整理
- 深入解析Mac OS X 与 iOS 操作系统
- WWDC 2018 Session 416 iOS Memory Deep Dive
- [ WWDC2018 ] - 深入解析iOS内存 iOS Memory Deep Dive
- WebKit MemoryFootprintCocoa
- Handling low memory conditions in iOS and Mavericks
- Minimizing your app's Memory Footprint
- About the Virtual Memory System
- iOS 内存管理研究
- iOS Memory Deep Dive
- 深入理解 CADisplayLink 和 NSTimer
- CADisplayLink
- CFRunLoop.c
- 计算机那些事(8)——图形图像渲染原理