
结构化并发
![]()
对于异步与并发,一直以来,业界都有着非常广泛的研究,针对特定场景提出了很多相关的技术,如:Future/Promise、Actor、CSP、异步函数等等。本文,我们来介绍一个近些年才出现的一个概念——结构化并发(Structured Concurrency)。
2016 年,ZeroMQ 的作者 Martin Sústrik 于在其 C 语言结构化并发库 libdill 中首次提出了“结构化并发”的概念。事实上,这个概念其实是受到了更早期 Dijkstra 所提出的 结构化编程(Structured Programming) 的启发。
为了引出结构化并发,我们首先来介绍一下什么是结构化编程,这一切要从 GOTO 有害论说起。
GOTO 有害论
计算机发展的早期,程序员使用汇编语言进行编程,在之后的一段时期,诞生了比汇编略微高级的编程语言,如 FORTRAN、FLOW-MATIC 等。这些语言虽然在一定程度上提高了可读性,但是仍然存在很大的局限性。如下所示就是一段 FLOW-MATIC 代码。

由于当时块语法还没有发明,因此 FLOW-MATIC 不支持 if
块、循环块、函数调用、块修饰符等现代语言必备的基础特性。整段代码就是一系列按顺序排列并打平的命令。关于控制流,程序支持两种方式,分别是:
- 顺序执行
- 跳转执行,即 GOTO 语句。

顺序执行的逻辑非常简单,它总是能够找到执行入口与出口。与之相反,跳转执行则充满了不确定性。如果程序中存在 GOTO 语句,那么它可以在 任何时候跳转至任何指令位置。一旦程序大量使用了 GOTO 语句,那么最终将变成 面条式代码(Spaghetti code)。
如下所示,我们对 FLOW-MATIC 代码的控制流使用箭头进行变标记,可以发现整个逻辑变成了一团糟,如同面条一般。

结构化编程
在发表 《Goto Statement Considered Harmful》 之后,Dijkstra 又发表了 《Notes on Structured Programming》 表达了其理想的编程范式,提出了 结构化编程 的概念。
结构化编程在现在看来是理所当然的,但是在当时并不是。结构化编程的核心是 基于块语句,实现代码逻辑的抽象与封装,从而保证控制流具有单一入口和单一出口。现代编程语言中的条件语句、循环语句、函数定义与调用都是结构化编程的体现。
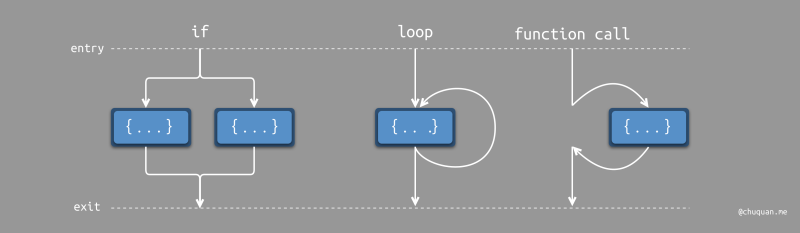
相比 GOTO 语句,基于块的控制流有一个显著的特征:控制流从程序入口进入,中途可能会经历条件、循环、函数调用等控制流转换,但是最终控制流都会从程序出口退出。这种编程范式使得代码结构变得更加结构化,思维模型变得更加简单,也为编译器在低层级提供了优化的可能。
因此,完全禁用 GOTO
语句已经成为了大部分现代编程语言的选择。虽然,少部分编程语言仍然支持
GOTO,但是它们大都支持高德纳(Donald Ervin
Knuth)所提出的前进分支和后退分支不得交叉的理论。类似
break、continue
等控制流命令,依然遵循结构化的基本原则:控制流拥有单一的入口与出口。
如今,我们基于现代编程语言所编写的程序,绝大部分都是结构化的,结构化编程范式早已深入人心。
并发编程
在单线程编程模型中,编程语言 通过代码块避免控制流随意跳转,从而实现程序的结构化。但是,在多线程编程(并发编程)模型中,线程之间控制和归属关系仍然存在很多问题,其面临的问题与 GOTO 的问题非常相似,这也是结构化并发所要解决的问题。
下面,我们先来看一下非结构化并发的问题。
非结构化并发
我们首先来看一个使用 Swift 编写的非结构化并发的例子,如下所示。
1 | func main() { |
上述代码中,主线程执行 main 方法是一个结构化的过程。而
main 和 foo
内部则以非阻塞的方式执行并发任务,并通过 completion
获取结果。bar 内部则以阻塞的方式执行计算任务,并调用
completion 返回结果。
进一步分析这段代码中各个方法,可以发现 main 和
foo 中的并发任务派发其实是一种函数间的无条件 “跳转”
行为。虽然,main 和 foo
都会立即将控制流返回至调用者,但是它们各自生成了新的并发任务。这些并发任务并不知道自己从哪里来,它们的初始调用不存在于其所属线程的调用栈中,其生命周期也与调用者的作用域完全无关。
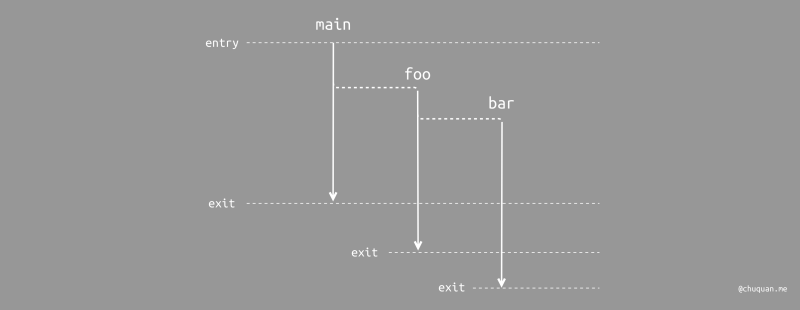
这样的非结构化并发不仅使得代码的控制流变得非常复杂,而且还会带来了一个致命的后果:由于和调用者具有不同的调用栈,因此无法得知原始的调用者,进而无法以抛出的方式向上传递错误。
在非结构化并发的编程范式下,我们在调用任意一个方法,我们都会存在很多担忧:
- 方法是否会产生一个后台任务?
- 方法虽然返回了,它所产生的后台任务是否仍然在运行?什么时候完成?其又会产生什么行为?
- 作为调用者,应该在哪里处理回调?如何处理回调?
- 是否保持这个方法用到的资源?后台任务是否会自动持有这些资源?还是要手动释放资源?
- 后台任务是否可以被管理?如果取消这些后台任务?
- 后台任务时候会产生其他后台任务?这些任务是否可以被正确管理?当任务取消时,二次派发的任务是否也会被取消?
这些问题都是非结构化并发可能存在的问题,而结构化并发正是为了解决这些问题而提出的。
结构化并发
那么,到底什么是结构化并发呢?结构化并发的核心是 在并发模型下,也要保证控制流的单一入口和单一出口。程序可以产生多个控制流来实现并发,但是所有并发控制流在出口时都应该处于完成或取消状态,控制流最终在出口处完成合并。
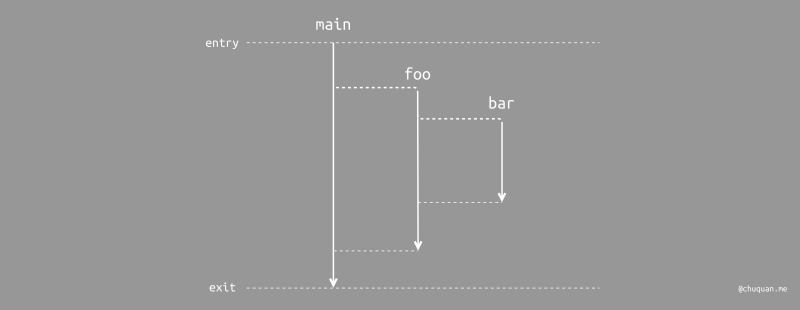
在结构化并发的编程范式下,foo
方法将所产生的并发控制流最终都会收束至 foo
方法中,main
方法也是如此,实现了真正的自包含。此时,我们调用黑盒方法,能够确信即使方法会产生额外的并发任务,控制流最终也会回归到方法调用的位置,一切尽在掌握之中!
通用实现模式
整体技术栈
大多数情况下,结构化并发的实现技术栈如下图所示。从上层到底层可以分为五个部分,分别是:
- 作用域(Scope)
- 异步函数(Async function)
- 协程(Coroutine)
- 计算续体(Continuation)
- 内核态线程(Kernel Thread)

作用域
结构化编程是以 代码块(Code Block)
为基本要素进行组织的,而结构化并发则是以
作用域(Scope)
为基本要素进行组织的。在不同的编程语言或技术框架中,对于作用域的命名所有不同,如:Kotlin
称为 Scope,Swift 称为 Task,Python trio 称为
nursery,C libdll 称为 bundle。
类似于块语法用于标注结构化编程中的代码逻辑块,作用域则用于标注并发操作的执行范围。下图所示,为作用域标识并发操作作用域的示意图。另外,作用域之间的关系只有包含和并列关系,而没有部分重叠关系,这一点与块语法规则相同。这使得作用域之间的关系变得非常清晰,而易于管理。
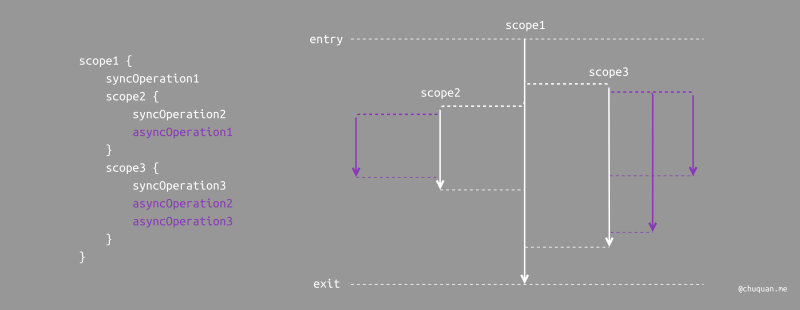
在基于作用域的实现模式下,很多并发问题变得简单很多,比如:
- 对于数据交换:以作用域为中心进行数据交互和传递,避免多线程数据操作导致问题。
- 对于返回值/异常传递:以作用域构成的关系链进行传递,类似于 UI 事件传递。
- 对于异步取消:以作用域为粒度,取消其所包含的异步任务以及子作用域,从而递归取消所有异步任务。
异步函数
很多编程语言都支持了异步函数,为了与同步函数进行区分,基本都提供了特定的关键词来进行声明或调用,比如:async/await,suspend、yield/resume
等。通过异步函数,我们可以通过同步调用的方式来编写代码,从而避免出现低于回调,进而提高代码的可读性。
如果编程语言只提供了异步函数,而不支持作用域,事实上也能够避免内部异步任务生命周期超出外部调用方法声明周期,因为异步函数的调用是通过以阻塞式的方式执行的。
相比而言,作用域的作用则在于管理多任务并发执行,解决多任务取消,值/异常传递等问题,这些是异步函数所无法解决的。
协程
对于并发任务本身,其运算调度则由线程来支持。但是在高并发的场景下,基于传统意义上的线程池可能会面临性能瓶颈,如:线程爆炸、线程切换等。
为了解决性能和效率问题,大部分支持结构化并发的编程语言都以 协程(Coroutine) 作为运算调度的最小单元。那么到底什么是协程?协程本质上就是 用户态线程,关于协程的进一步介绍可以阅读我之前写过的一篇博客—— 《初识协程》。
我们知道操作系统线程模型主要有 3 种,如下图所示。其中,纯用户态线程模型是早期单核 CPU 的产物,纯内核态线程模式是多核 CPU 下相对高效的模型。现代操作系统普遍采用的是组合式线程模型,支持提供远超 CPU 核心数量的用户态线程池。用户态线程的切换不涉及线程资源(包括寄存器、栈指针、栈内存等)切换,因此性能开销相对较小。

在传统的同步编程模式下,我们始终维护一个线性的调用栈,而在基于作用域和协程实现的并发编程模式下,我们可以维护一个树形的调用栈,如下图所示。基于树形调用栈,我们可以有效记录父子并发任务之间的调用关系,便于问题定位与追踪。注意,协程可以根据是否基于调用栈实现,分为有栈协程和无栈协程,这里我们以有栈协程为例,介绍结构化并发的优势。

计算续体
在代码层面,异步函数之后的代码是怎么实现等待异步函数执行完成之后再执行的呢?试想一下如下这段伪代码,为什么
print result 会等待异步函数 asyncOperation
完成之后才会执行的呢?怎么做到的?
val result = await asyncOperation()
print result事实上,这样要归功于 计算续体(Continuation)。知道回调函数的人很多,但是知道计算续体的人并不多。当一个计算过程在中间被打断,其剩余部分可以使用一个对象进行表示,这个对象就是计算续体。当然,操作系统暂停一个线程时保存的那些数据快照,也可以看成是一个计算续体。基于计算续体,我们就能实现从上次中断的地方继续执行。

既然可以利用续体来等待异步操作执行完成,那么执行过程中运行时系统是如何选择哪些部分作为续体呢?对此,大多数编程语言会提供相关的关键词进行修饰,最常见的就是
async 和 await。一般 async
用于声明一个异步函数,await
用于挂起(执行)一个异步函数。事实上,计算续体就是异步函数的底层实现技术。
当使用 await 调用一个异步函数时,那么编译器会
将后续部分的代码转换成续体,当异步任务执行完毕之后,再将值传递至续体中继续执行,有点类似于方法回调。
在不同的编程语言中,计算续体的表示也有所不同。Kotlin 和 Swift 使用
Continuation 表示,Lua 使用 Coroutine Object
表示,JavaScript 使用 Generator 表示,Dart 使用
Async Generator 表示。
续体与栈帧
事实上,计算续体与函数栈帧有着非常紧密的关系,前者是保存和恢复栈帧的一种机制。
在函数调用时,每个函数都会创建一个栈帧,其包含函数的局部变量、参数以及返回地址等信息。栈帧被存放在进程空间的栈区,当函数返回时,对应的栈帧会从栈中弹出,程序恢复到调用该函数的地方。
计算续体则是将 当前栈帧 以及 程序计算器 等信息保存至一个对象中,然后将该对象传递给一个续体函数。续体函数可以在需要时将保存的状态恢复,从而继续执行程序。
因此,从运行时层面看,计算续体就是当前函数的栈帧与现场状态;从代码层面看,计算续体就是等待异步操作完成的后续代码。
CPS 变换
提到计算续体,我们就不得不提一下 CPS 变换(Continuation-Passing-Style Transformation)。
CPS 变换本质上就是
将等待执行的代码转换成一个函数,计算续体作为函数的参数,参数名通常命名成
Continuation。
下面,我们以 Swift 为例进行介绍。假如,我们有一个旧版
oldLoad
方法,通过闭包进行异步回调。此时,我们希望设计基于异步函数的新版
newLoad 方法,但是内部仍然使用旧版 oldLoad
方法进行复用。在这种场景下,我们就可以利用 CPS 变换来实现预期目标。
1 | # 旧版方法 |
下图所示,当我们使用新版 newLoad
方法时,等待异步执行的代码被封装成了一个函数,函数的参数是一个
Continuation。我们可以根据不同的情况向
Continuation
传递值或错误,从而让等待异步执行的代码继续执行。
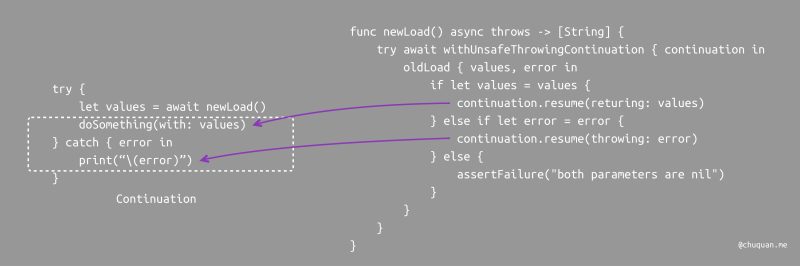
事实上,Kotlin 协程就是通过 CPS 转换实现的,其在编译期间对调用挂起函数的上下文进行拆分,完成 CPS 转换。这也是为什么 Kotlin 可以不用修改 VM 或 OS 就能够支持协程的原因。
并发调度模型
通过上一节我们知道了结构化并发所涉及的各种技术。下面,我们来通过一段 Swift 代码,介绍一下并发任务的调度模型。
1 | func save(_ contents: [Contents]) async throws -> [ID] { ... } |
假设一个线程调用了一个 handle
方法。在这个阶段,最近的堆栈将是 handle。当
handle 遇到内部的 await
关键词修饰的异步操作时,运行时会将 handle
方法的计算续体存储至堆中,从而等待异步操作完成。

当运行时发现存在空闲的线程时,则将异步操作 save
加入对应线程的栈中并开始执行。但是 save 方法内部又存在异步
I/O 操作,因此 save
方法的计算续体又会被存储至堆中,从而等待 I/O 操作完成。

在等待 I/O
操作的过程中,线程会被让出,从而允许其他任务进行复用。下图中,运行时会将
otherWork1 方法加入线程并执行。
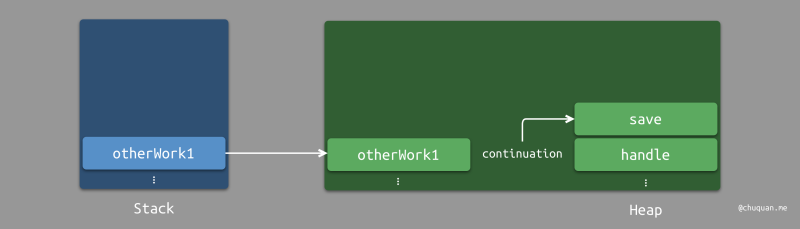
当 save 所等待的 I/O
操作完成之后,运行时会寻找空闲的线程,并将 save
的计算续体加入栈中并执行。

当 save 执行完毕,运行时会将与 save
计算续体关联等待的 handle
续体取出,选择一个空闲的线程来执行。

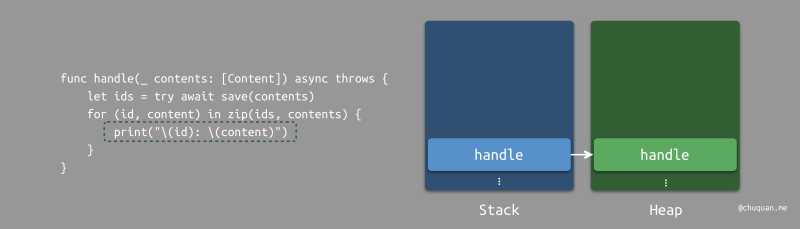
在 handle 计算续体执行过程中,会调用同步方法如
zip,那么栈上将会正常加入 zip 的栈帧。

zip 执行完毕之后,对应的栈帧出栈,继续执行
hanle 计算续体。由于这里是一个 for
循环,zip
栈帧的入栈和出栈会循环往复多次。最终,handle
计算续体也执行完毕。
总结
本文通过 GOTO 有害论引出编程历史中结构化编程的演化。以结构化编程作为类比,介绍了结构化并发的核心观点,以及结构化并发的设计理念。结构化并发主要包括作用域、异步函数、计算续体、协程等技术,此外还需要运行时系统的调度,才能最终实现理想的结构化并发。
关于高级编程语言中结构化并发的实践,后续我们将继续在其他文章中进行讨论。目前原生支持结构化并发的编程语言并不多,幸运的是移动端开发的编程语言 Kotlin、Swift 是支持的,后面我们会研究一下这两者对于结构化并发的实现。另外,有时间的话,我们也会介绍一些结构化并发的辅助框架,比如:trio、libdll 等,进而加深对于结构化并发的理解。
参考
- Continuation
- Structured concurrency
- Structured programming
- Structured Programming with go to Statements
- Go To Statement Considered Harmful
- Notes on structured programming
- Notes on structured concurrency, or: Go statement considered harmful
- Structured Concurrency
- Structured Concurrency in High-level Languages
- Structured Concurrency Finding our way out of callback hell
- Some thoughts on asynchronous API design in a post-async/await world
- Structured concurrency resources
- Structured Concurrency Kickoff
- Structured concurrency
- KotlinConf 2017 - Introduction to Coroutines by Roman Elizarov
- Structured concurrency and Lua(part1)
- Structured concurrency and Lua(part2)
- Structured concurrency and Lua(part2)
- Explore structured concurrency in Swift
- Swift concurrency: Behind the scenes
- 《swift 异步与并发》
- Kotlin协程 - 先入个门吧
- Kotlin协程