
基于 LLVM 自制编译器(5)——语言扩展:控制流
概述
在前 4 章中,我们介绍了 Kaleidoscope 语言的实现,包括支持 LLVM IR
代码生成、优化器、JIT 编译器等。然而,目前我们设计的 Kaleidoscope
的功能非常简单,除了函数调用和返回外,甚至不包含控制流的能力。这意味着我们在代码中无法使用条件分支,因此极大地限制了编程语言的能力。本章,我们将对
Kaleidoscope 进行扩展,使其支持 if/then/else 语句和
for 语句。
if/then/else
为 Kaleidoscope 进行语言扩展 if/then/else
语句其实非常简单。我们只需要修改词法分析器、解析器、AST、LLVM
代码生成器就可以实现这个新的特性。
在我们介绍如何实现该特性之前,我们首先需要清楚这个特性是什么。本质上,我们其实就是就是希望
Kaleidoscope 能够支持如下所示的代码。 1
2
3
4
5def fib(x)
if x < 3 then
1
else
fib(x-1)+fib(x-2);
在第 2 章中,我们为 Kaleidoscope 的 AST 设计了三种结构,分别是
表达式、原型、函数。其中,表达式结构均会返回一个值,而
if/then/else
同样也会返回一个值。本质上,if/then/else
语句是先对条件进行计算,然后根据条件的结果选择返回 then 或
else 的值。因此,我们定义一个表达式子类用于表示
if/then/else 语句。
if/then/else
的语义是将条件的计算结果作为一个布尔等价值:0.0 表示
false,其他值则为 true。如果条件为
true,则计算并返回第一个子表达式;如果条件为
false,则计算并返回第二个子表达式。
下面,我们来对各个部分进行扩展从而实现 if/then/else
表达式。
词法分析器扩展
词法分析器的扩展非常简单。首先,我们需要新增几种 token
类型,如下所示。 1
2
3
4// control
tok_if = -6,
tok_then = -7,
tok_else = -8,
然后,我们分别为这些 token 类型定义 token 值,如下所示。
1
2
3
4
5
6
7
8
9
10
11
12...
if (IdentifierStr == "def")
return tok_def;
if (IdentifierStr == "extern")
return tok_extern;
if (IdentifierStr == "if")
return tok_if;
if (IdentifierStr == "then")
return tok_then;
if (IdentifierStr == "else")
return tok_else;
return tok_identifier;
AST 扩展
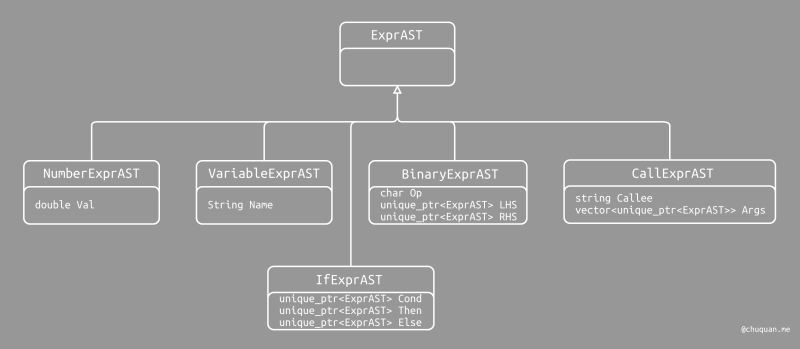
为了表示 if/then/else 语句,我们定义一个表达式子类的 AST
节点类型 IFExprAST,如下所示。IFExprAST
节点包含三个指针,分别指向 Cond 子表达式、Then
子表达式、Else 子表达式。 1
2
3
4
5
6
7
8
9
10
11/// IfExprAST - Expression class for if/then/else.
class IfExprAST : public ExprAST {
std::unique_ptr<ExprAST> Cond, Then, Else;
public:
IfExprAST(std::unique_ptr<ExprAST> Cond, std::unique_ptr<ExprAST> Then,
std::unique_ptr<ExprAST> Else)
: Cond(std::move(Cond)), Then(std::move(Then)), Else(std::move(Else)) {}
Value *codegen() override;
};
解析器扩展
至此,我们已经有了针对 if/then/else 的 token 的定义和
AST 节点定义。接下来,我们来对解析器进行扩展。
首先,我们来定义一个对应的解析函数。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28/// ifexpr ::= 'if' expression 'then' expression 'else' expression
static std::unique_ptr<ExprAST> ParseIfExpr() {
getNextToken(); // eat the if.
// condition.
auto Cond = ParseExpression();
if (!Cond)
return nullptr;
if (CurTok != tok_then)
return LogError("expected then");
getNextToken(); // eat the then
auto Then = ParseExpression();
if (!Then)
return nullptr;
if (CurTok != tok_else)
return LogError("expected else");
getNextToken();
auto Else = ParseExpression();
if (!Else)
return nullptr;
return std::make_unique<IfExprAST>(std::move(Cond), std::move(Then), std::move(Else));
}
接下来,我们将解析函数加入到主表达式解析函数中,如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14static std::unique_ptr<ExprAST> ParsePrimary() {
switch (CurTok) {
default:
return LogError("unknown token when expecting an expression");
case tok_identifier:
return ParseIdentifierExpr();
case tok_number:
return ParseNumberExpr();
case '(':
return ParseParenExpr();
case tok_if:
return ParseIfExpr();
}
}
LLVM IR
至此,我们已经解析并构造了 AST。接下来,我们来为
if/then/else 支持 LLVM IR
代码生成。上述扩展的相关代码在之前的章节中都已经进行了详细的介绍,而这部分的扩展,我们将引入一些新的概念。
我们首先来看一个简单的例子,如下所示。 1
2
3extern foo();
extern bar();
def baz(x) if x then foo() else bar();
如果,我们不进行代码优化,生成的代码会是如下所示。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21declare double @foo()
declare double @bar()
define double @baz(double %x) {
entry:
%ifcond = fcmp one double %x, 0.000000e+00
br i1 %ifcond, label %then, label %else
then: ; preds = %entry
%calltmp = call double @foo()
br label %ifcont
else: ; preds = %entry
%calltmp1 = call double @bar()
br label %ifcont
ifcont: ; preds = %else, %then
%iftmp = phi double [ %calltmp, %then ], [ %calltmp1, %else ]
ret double %iftmp
}
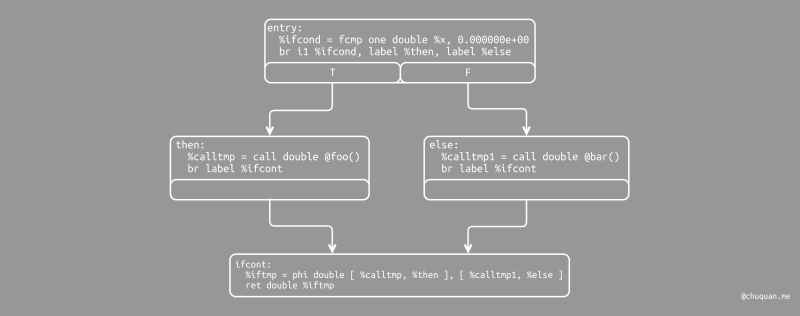
在 LLVM IR 中,entry
基本块对条件表达式进行计算(结果存储在 x 中),并使用
fcmp one(one 表示
Ordered and Ont Equal)命令将结果值与 0.0
进行比较。然后,根据表达式的结果决定代码跳转至 then
基本块或 else 基本块。
当 then/else 基本块执行完毕,它们均会进入
ifcont 基本块,从而执行 if/then/else
表达式后续的代码。在例子中,我们只需返回至函数调用者即可。
φ 函数
在上述例子中,我们最终会向函数调用者返回一个表达式,那么问题来了:代码是否如何知道应该返回哪个表达式?答案是通过 phi 操作实现。
在第 3 章,我们提到 LLVM 的 Value 是用来表示
静态单赋值形式(SSA form) 的类型,LLVM IR 则是 SSA
的指令表示形式。当我们对基于 SSA
形式的控制流图进行分析时,如果有两条控制流边汇合到一起时,如何使每个变量只有一次赋值就不是那么显而易见的了。如下所示
(a) 图中,如果我们在基本块 1 和基本块 3 中分别为 a
实现了一次定值,那么基本块 4 该使用哪个值呢?
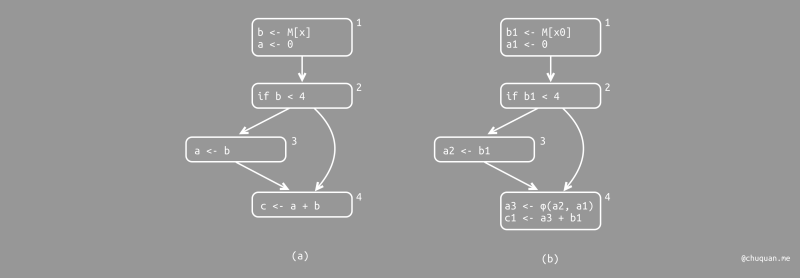
为了解决这个问题,我们引入一个虚构符号,称为
φ函数。如上所示 (b) 图中,使用
a3 <- φ(a1, a2) 来合并 a1(基本块 1
中的定值)和 a2(基本块 3 中的定值)。 如果控制流沿边 2
-> 4 到达基本块 4,φ(a1, a2) 产生 a1;如果控制流沿边 3 -> 4
到达基本块 4,φ(a1, a2) 产生 a2。
在 LLVM IR 中,使用 phi 指令实现 φ
函数。在例子中,如果控制流来自 then 基本块,那么
phi 指令会读取 calltmp 的值,如果控制流来自
else 基本块,那么 phi 指令会读取
calltmp1 的值。
代码生成
如下所示为 IFExprAST 类的 codegen
方法,用于 LLVM IR 代码生成。我们依次对这个方法的各个部分进行介绍。
1
2
3
4
5
6
7
8Value *IfExprAST::codegen() {
Value *CondV = Cond->codegen();
if (!CondV)
return nullptr;
// Convert condition to a bool by comparing non-equal to 0.0.
CondV = Builder->CreateFCmpONE(
CondV, ConstantFP::get(*TheContext, APFloat(0.0)), "ifcond");
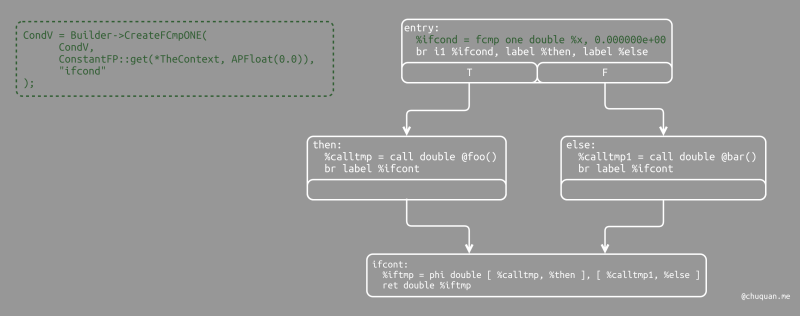
首先,我们解析得到条件表达式,并通过将其值与 0.0 进行比较,从而转换成一个布尔类型。上图所示,展示了这部分逻辑生成的代码。
1 | Function *TheFunction = Builder->GetInsertBlock()->getParent(); |

其次,分别为 if/then/else
语句创建相关基本块,如:ThenBB、ElseBB、MergeBB。这里,其首先获取当前正在构建的
Function 对象。基于 Function
对象,创建三个基本块。注意,这里将 TheFunction 传入
then 基本块的构造函数,其用于将新创建的基本块插入到指定函数
TheFunction
的末尾。其他两个基本块创建后并没有立即插入函数。当基本块创建完成后,我们通过
Builder->CreateCondBr 方法创建条件分支。
1 | // Emit then value. |
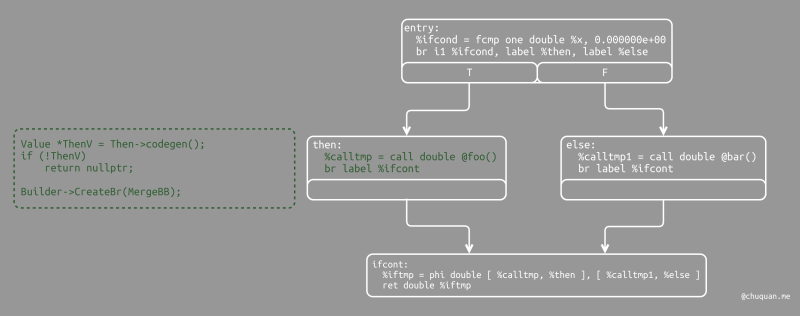
随后,我们设置 Builder 中基本块的插入点并开始插入
then
基本块。严格来说,它会将插入点移动到指定基本块的末尾。但是,由于此时
then 基本块是空的,所以它也是在块的开头开始插入。
当插入点设置完成后,我们递归地为 then
表达式生成代码。为了完成 then 基本块,我们为无条件分支创建
merge 基本块。LLVM IR 要求所有基本块都使用诸如返回
ret 或分支 br
的控制流指令来终止。这意味着我们必须在 LLVM IR 中明确所有控制流,包括
fall through。如果我们没有遵循这个规则,后续的验证器会报错。
这里的最后一行非常微妙,但也非常重要。这里的问题在于,当我们在
merge 基本块中创建 phi 节点时,我们需要设置 phi
要处理的块/值对。然而,phi
节点希望控制流图中每个基本块都有一个入口。那么,我们为什么要执行
ThenBB 之前的 5 行代码呢?问题是 Then
表达式本身可能实际上改变了 Builder
生成的基本块,比如,它包含了一个嵌套的 if/then/else
表达式。因为递归调用 codegen()
可以任意修改当前基本块,所以我们需要获取将设置 phi
节点的代码的最新值。
1 | // Emit else block. |
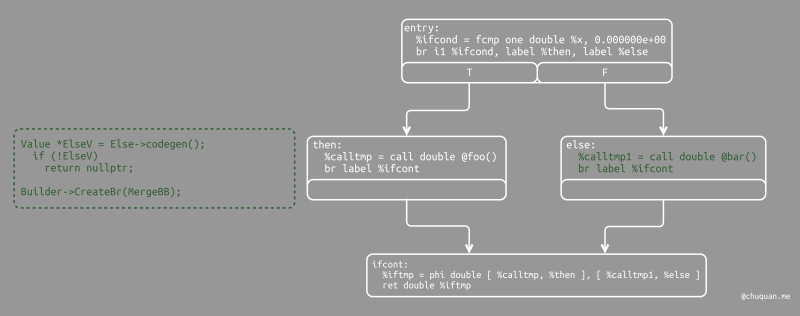
else 基本块的代码生成与 then
基本块的代码生成基本相同。唯一的区别在于第一行,它将 else
基本块添加到了函数中。至此,then 基本块和 else
基本块都已创建完成,接下来我们可以进行合并。
1 | // Emit merge block. |
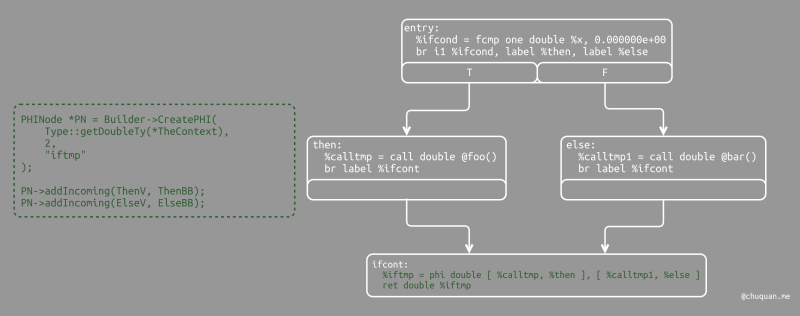
这里的前两行代码我们很熟悉:
- 第一行将
merge基本块添加到Funciton对象 - 第二行修改插入点,以便新创建的代码将进入
merge基本块
然后,我们创建 phi 节点,并为它设置块/值对。
最后,codegen 方法将 phi 节点作为
if/then/else
表达式的值进行返回。在上述例子中,该返回值将输入到顶级函数的代码中,该函数将创建返回指令。
for 循环
通过上面的实践,我们了解了如何为编程语言扩展控制流结构。接下来,我们来继续为
Kaleidoscope 支持 for 循环,如下所示。 1
2
3
4
5
6
7extern putchard(char);
def printstar(n)
for i = 1, i < n, 1.0 in
putchard(42); # ascii 42 = '*'
# print 100 '*' characters
printstar(100);
for
语句定义了一个新的变量,变量从起始值开始迭代,当条件为真时,使用步长值进行递增。如果省略步长值,则默认为
1.0。当条件为真时,执行内部的表达式。
下面,我们来看一下如何进行扩展。
词法分析器扩展
与 if/then/else 扩展类似,对于 for
语句,我们为词法分析器新增了两个 token 类型和 token 值,如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21... in enum Token ...
// control
tok_if = -6, tok_then = -7, tok_else = -8,
tok_for = -9, tok_in = -10
... in gettok ...
if (IdentifierStr == "def")
return tok_def;
if (IdentifierStr == "extern")
return tok_extern;
if (IdentifierStr == "if")
return tok_if;
if (IdentifierStr == "then")
return tok_then;
if (IdentifierStr == "else")
return tok_else;
if (IdentifierStr == "for")
return tok_for;
if (IdentifierStr == "in")
return tok_in;
return tok_identifier;
AST 扩展
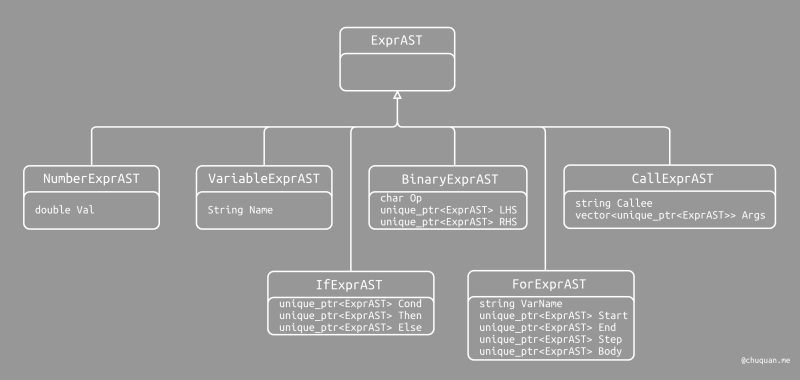
为了表示 for 语句,我们定义一个表达式子类的 AST 节点类型
ForExprAST。ForExprAST 包含四个指针,分别指向
Start,End,Step,Body
子表达式,此外还包含一个变量 VarName。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/// ForExprAST - Expression class for for/in.
class ForExprAST : public ExprAST {
std::string VarName;
std::unique_ptr<ExprAST> Start, End, Step, Body;
public:
ForExprAST(const std::string &VarName,
std::unique_ptr<ExprAST> Start,
std::unique_ptr<ExprAST> End,
std::unique_ptr<ExprAST> Step,
std::unique_ptr<ExprAST> Body)
: VarName(VarName), Start(std::move(Start)), End(std::move(End)),
Step(std::move(Step)), Body(std::move(Body)) {}
Value *codegen() override;
};
解析器扩展
如下所示为 for 表达式的解析函数。for
表达式支持可选的步长值,对此,解析函数通过检查是否存在第二个逗号来进行处理步长值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48/// 文法产生式
/// forexpr ::= 'for' identifier '=' expr ',' expr (',' expr)? 'in' expression
static std::unique_ptr<ExprAST> ParseForExpr() {
getNextToken(); // eat the for.
if (CurTok != tok_identifier)
return LogError("expected identifier after for");
std::string IdName = IdentifierStr;
getNextToken(); // eat identifier.
if (CurTok != '=')
return LogError("expected '=' after for");
getNextToken(); // eat '='.
auto Start = ParseExpression();
if (!Start)
return nullptr;
if (CurTok != ',')
return LogError("expected ',' after for start value");
getNextToken();
auto End = ParseExpression();
if (!End)
return nullptr;
// The step value is optional.
std::unique_ptr<ExprAST> Step;
if (CurTok == ',') {
getNextToken();
Step = ParseExpression();
if (!Step)
return nullptr;
}
if (CurTok != tok_in)
return LogError("expected 'in' after for");
getNextToken(); // eat 'in'.
auto Body = ParseExpression();
if (!Body)
return nullptr;
return std::make_unique<ForExprAST>(IdName, std::move(Start),
std::move(End), std::move(Step),
std::move(Body));
}
与 if/then/else 相同,我们也把 ParseForExpr
解析函数方法插入到主表达式的解析函数 ParsePrimary 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16static std::unique_ptr<ExprAST> ParsePrimary() {
switch (CurTok) {
default:
return LogError("unknown token when expecting an expression");
case tok_identifier:
return ParseIdentifierExpr();
case tok_number:
return ParseNumberExpr();
case '(':
return ParseParenExpr();
case tok_if:
return ParseIfExpr();
case tok_for:
return ParseForExpr();
}
}
LLVM IR
下面,我们来为 for 表达式生成 LLVM
IR。我们将上面的例子进行转换成得到如下所示的 LLVM IR 代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24declare double @putchard(double)
define double @printstar(double %n) {
entry:
; initial value = 1.0 (inlined into phi)
br label %loop
loop: ; preds = %loop, %entry
%i = phi double [ 1.000000e+00, %entry ], [ %nextvar, %loop ]
; body
%calltmp = call double @putchard(double 4.200000e+01)
; increment
%nextvar = fadd double %i, 1.000000e+00
; termination test
%cmptmp = fcmp ult double %i, %n
%booltmp = uitofp i1 %cmptmp to double
%loopcond = fcmp one double %booltmp, 0.000000e+00
br i1 %loopcond, label %loop, label %afterloop
afterloop: ; preds = %loop
; loop always returns 0.0
ret double 0.000000e+00
}if/then/else
中相同的结构:一个 phi
节点、几个表达式和一些基本块。下面,让我们看看它们是如何组合在一起的。
代码生成
codegen 的第一部分非常简单,为 Start
表达式生成代码,如下所示。
1 | Value *ForExprAST::codegen() { |
随后,我们为循环体的开始设置 LLVM
基本块。在上面的例子中,整个循环体是一个基本块,而循环体代码本身可以由多个基本块组成(例如,如果它包含嵌套的
if/then/else 或 for/in 表达式)。
1 | // Make the new basic block for the loop header, inserting after current |
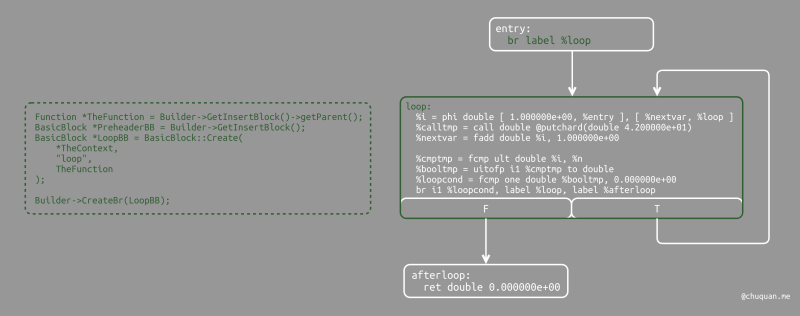
第二部分的代码与 if/then/else 非常相似。由于我们需要创建
phi
节点,因此要记住会进入循环的基本块。当我们获取到此基本块后,我们创建一个实际启动循环的基本块
PreheaderBB ,并为两个基本块创建一个无条件分支。
1 | // Start insertion in LoopBB. |
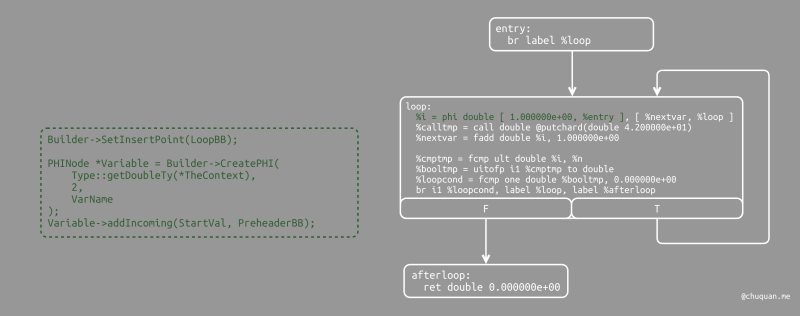
至此,我们已经设置了循环的 PreheaderBB
基本块,我们开始为循环体生成代码。首先,我们移动插入点,并为循环归纳变量创建
phi 节点。由于我们已经知道起始值的传入值,我们将其加入至 phi
节点。注意,phi
节点最会获得第二个值作为另一个边界,但是,目前我们还无法进行设置,因为它不存在。
1 | // Within the loop, the variable is defined equal to the PHI node. If it |
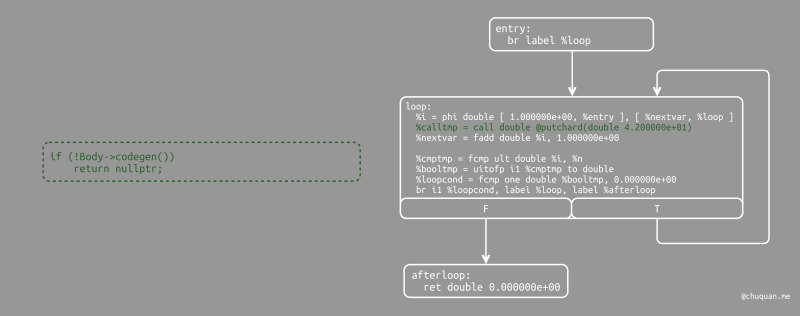
此时,for 将会向符号表中引入循环变量
VarName,从而使得符号表能够包含函数参数、循环变量等。为此,我们在为循环体生成代码之前,必须要将循环变量加入符号表,并存储其当前的值。注意,在外层作用域中有可能存在同名的变量
VarName,这里将符号表中的外部同名变量的值暂存至
OldVal 局部变量中,当代码生成完毕后,再进行恢复。
当循环变量存入符号表后,我们为循环体生成代码。这允许循环体使用循环变量:任何对于循环变量的引用都会通过符号表进行查找。
1 | // Emit the step value. |
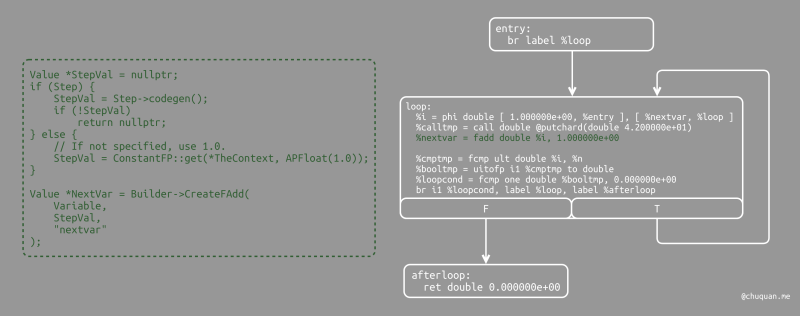
至此,循环体代码生成完毕,我们将通过增加步长值(如果没有则为
1.0)来计算迭代变量的下一个值。NextVar
将是循环的下一次迭代时循环变量的值。
1 | // Compute the end condition. |
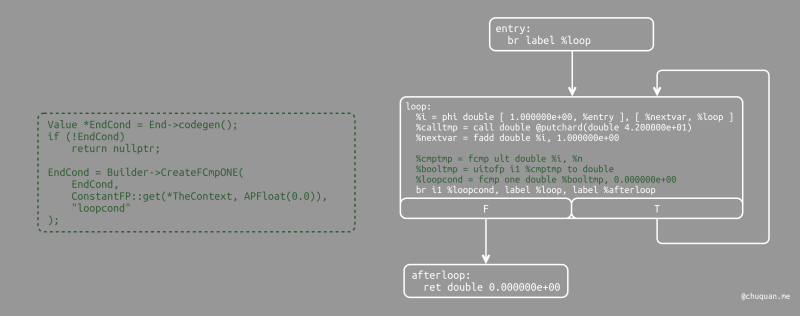
最后,我们计算循环的退出值,从而决定循环是否退出。这与
if/then/else 语句的条件判断类似。
1 | // Create the "after loop" block and insert it. |
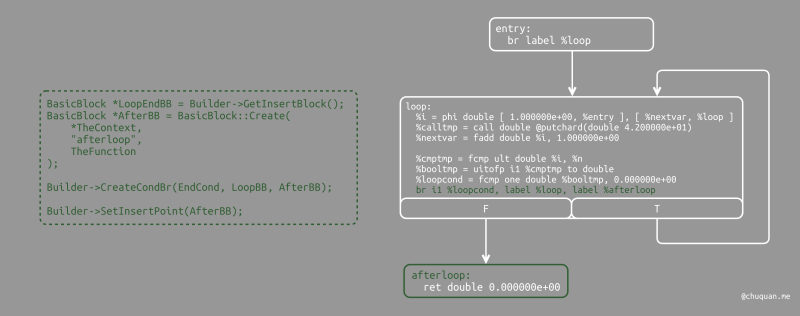
当循环体代码生成完成,我们只需要处理结束后的控制流。这里,首先创建一个基本块用于循环退出(afterloop)。基于退出条件的值,创建一个条件分支用于选择再次执行循环或退出循环。后续的代码则位于
afterloop 基本块中,因此设置了对应的插入点。
1 | // Add a new entry to the PHI node for the backedge. |

最后一部分代码则进行了各种清理操作。至此,我们有了
NextVar 的值,因此我们可以将传入的值加入到 phi
节点中。之后,我们将循环变量从符号表中删除,使得其不属于循环以外的作用域。最后,循环的代码生成会返回
0.0,即 ForExprAST::codegen() 的返回值。
总结
至此,我们为 Kaleidoscope 实现了控制流能力,包括
if/then/else 和 for/in
两种结构。我们通过实现这两种控制流,并介绍了 LLVM IR 相关的概念,如:φ
函数。下一章,我们将进一步对 Kaleidoscope
进行扩展,支持自定义运算符的能力。