
基于 LLVM 自制编译器(4)——代码优化器、JIT 编译器
概述
前面几章我们介绍了如何实现一门简单的编程语言,同时支持了 LLVM IR 代码生成。本文,我们将介绍并实现两类技术:
- 代码优化器
- JIT 编译器
常量合并优化
在第 3 章中,我们实现了 LLVM IR
代码生成的能力。不过,生成的代码仍然具有很大的优化空间。当然,我们所使用的
IRBuider 对代码也进行了一定程度的优化,如下所示。
1
2
3
4
5
6
7ready> def test(x) 1+2+x;
Read function definition:
define double @test(double %x) {
entry:
%addtmp = fadd double %x, 3.000000e+00
ret double %addtmp
}IRBuilder
对代码进行了常量合并优化。如果根据输入内容进行 AST
构建,基于字面含义生成的代码则将如下所示。 1
2
3
4
5
6
7
8ready> def test(x) 1+2+x;
Read function definition:
define double @test(double %x) {
entry:
%addtmp = fadd double 2.000000e+00, 1.000000e+00
%addtmp1 = fadd double %addtmp, %x
ret double %addtmp1
}
常量合并(Contants Folding)是一种非常常见且重要的优化方法,几乎所有编程语言都在其 AST 中实现了常量合并优化。
在使用 LLVM 时,我们无需显式地开启常量合并优化功能,因为 LLVM IR 构造器内部会自动检测并执行常量合并。
事实上,我们通常建议使用 IRBuilder
来生成代码。IRBuilder 在构建过程中没有
语法开销(Syntactic
Overhead),即无需显式指定编译器进行常量检查。此外,还能够显著减少某些情况下的
LLVM IR 代码量。
当然,IRBuilder
也有一定的限制,其在生成代码时将所有分析的代码进行内联,从而会导致无法探测到某些优化点。比如:
1
2
3
4
5
6
7
8
9ready> def test(x) (1+2+x)*(x+(1+2));
ready> Read function definition:
define double @test(double %x) {
entry:
%addtmp = fadd double 3.000000e+00, %x
%addtmp1 = fadd double %x, 3.000000e+00
%multmp = fmul double %addtmp, %addtmp1
ret double %multmp
}LHS 和
RHS 是相同的值。我们期望生成的代码是
tmp = x+3; result = tmp * tmp,而不是计算两次
x+3。
遗憾的是,本地分析很难探测并纠正类似的优化点。这里,我们需要两种优化方式才能消除例子中冗余的
fadd 指令,分别是:
- 表达式重联(Reassociation Of Expression)
- 公共子表达式消除(Common Subexpression Elimination)
对此,LLVM 以 通道(Pass) 的形式提供了各种类型的优化,其中就包含上述的两种优化方式。
代码优化器
LLVM 为各种类型的优化提供了对应的优化通道(下文简称
Pass)。与其他系统不同,LLVM
并没有错误地认为某一组优化适用于所有编程语言和所有情况。相反,LLVM
允许编译器开发者自定义选择哪些优化、以哪种顺序优化、在哪种情况下优化。
比如,LLVM 提供了 whole module
Pass,其能够尽可能多地查看代码体(通常是整个文件,如果在链接时执行,那么它可能是整个程序的很大一部分)。LLVM
还支持 per-function
Pass,其一次只对一个函数进行操作,而不查看其他函数。关于 Pass
的更多细节,可以查看官方文档——How to Write a
Pass、LLVM’s Analysis
and Transform Passes。
现阶段,当用户输入代码时,我们会实时生成 LLVM
IR。在实时解析过程中,我们会在用户输入代码时运行
per-function Pass
进行优化。如果我们想实现一个“静态编译器”,我们可以完全使用现有的代码,不同的是,我们只会在整个文件被解析完成之后,才运行优化器。
为了执行 per-function Pass,我们需要设置一个
FunctionPassManager 来管理我们希望运行的 LLVM 优化通道。当
FunctionPassManager
设置完成后,我们可以向其注册一组优化通道来执行。对于每一个
Module,需要创建一个对应的
FunctionPassManager,因此我们可以实现一个函数来为完成创建并初始化模块和通道管理器,如下所示。
1 | void InitializeModuleAndPassManager(void) { |
上述代码中,首先初始化了全局模块 TheModule 和通道管理器
TheFPM,后者被附加到了 TheModule
中。当通道管理器初始化完毕,我们通过调用 add
方法来添加一系列 LLVM 优化通道。

这里,我们添加了 4 种优化通道,包括:窥孔优化、表达式重联、公共子表达式消除、控制流图简化 等。这是一组非常标准的代码清理优化,可用于各种代码。
当通道管理器初始化完毕后,我们会在
FunctionAST::codegen()
方法的末尾来调用并执行通道管理器,最终将优化结果返回,如下所示。
1
2
3
4
5
6
7
8
9
10
11
12if (Value *RetVal = Body->codegen()) {
// Finish off the function.
Builder.CreateRet(RetVal);
// Validate the generated code, checking for consistency.
verifyFunction(*TheFunction);
// Optimize the function.
TheFPM->run(*TheFunction);
return TheFunction;
}
从代码中可以看出,通道管理器的执行非常简单。FunctionPassageManager
直接对 LLVM Funtion*
进行优化和更新。我们可以对它进行简单的测试,如下所示。 1
2
3
4
5
6
7
8ready> def test(x) (1+2+x)*(x+(1+2));
ready> Read function definition:
define double @test(double %x) {
entry:
%addtmp = fadd double %x, 3.000000e+00
%multmp = fmul double %addtmp, %addtmp
ret double %multmp
}fadd 指令。
LLVM 为不同的场景提供了各种类型的优化。官方文档 LLVM’s Analysis and Transform
Passes
列出了一部分优化相关的通道,但不是非常完整。此外,我们也可以查看 Clang
启动时所执行的通道,还可以通过 opt 工具来试验通道。
JIT 编译器
LLVM 提供了非常多的工具,以支持操作 LLVM IR。例如:我们可以对 LLVM IR 执行各种类型的优化(如上文所示),可以将 LLVM IR 转换成文本形式或二进制形式,可以将 LLVM IR 编译成特定架构的汇编代码,可以对 LLVM IR 进行即时编译(JIT,Just In Time)。LLVM IR 的核心作用是作为编译器不同部分之间的通用传递形式。
在这一节中,我们将为 Kaleidoscope 实现 JIT 编译器。JIT
的基本思想是:当用户输入代码时,即时分析并评估其顶层表达式。比如:当用户输入
1+2; 时,我们将输出 3。
对此,我们首先准备相关环境,包括:
- 初始化本机目标(Native Target):通过调用
InitializeNativeTarget相关方法实现。 - 初始化 JIT:通过设置
KaleidoscopeJIT类型的TheJIT全局变量实现。
1 | static std::unique_ptr<KaleidoscopeJIT> TheJIT; |
此外,我们还需要为 JIT 设置数据内存布局,如下所示: 1
2
3
4
5
6
7
8
9void InitializeModuleAndPassManager(void) {
// Open a new module.
TheContext = std::make_unique<LLVMContext>();
TheModule = std::make_unique<Module>("my cool jit", *TheContext);
TheModule->setDataLayout(TheJIT->getDataLayout());
// Create a new pass manager attached to it.
TheFPM = std::make_unique<legacy::FunctionPassManager>(TheModule.get());
...
KaleidoscopeJIT 类表示针对 Kaleidoscope 语言的
JIT。在后续的章节中,我们将介绍它是如何工作的,并使用新功能对其进行扩展。它的
API 非常简单,包括:
addModule:用于向 JIT 注册 LLVM IR module,使其函数可用于执行。lookup:允许我们查找指向已编译代码的指针。
我们在顶层表达式解析函数中调用 KaleidoscopeJIT 的
AIP,如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28static void HandleTopLevelExpression() {
// Evaluate a top-level expression into an anonymous function.
if (auto FnAST = ParseTopLevelExpr()) {
if (FnAST->codegen()) {
// Create a ResourceTracker to track JIT'd memory allocated to our
// anonymous expression -- that way we can free it after executing.
auto RT = TheJIT->getMainJITDylib().createResourceTracker();
auto TSM = ThreadSafeModule(std::move(TheModule), std::move(TheContext));
ExitOnErr(TheJIT->addModule(std::move(TSM), RT));
InitializeModuleAndPassManager();
// Search the JIT for the __anon_expr symbol.
auto ExprSymbol = ExitOnErr(TheJIT->lookup("__anon_expr"));
// Get the symbol's address and cast it to the right type (takes no
// arguments, returns a double) so we can call it as a native function.
double (*FP)() = (double (*)())(intptr_t)ExprSymbol.getAddress();
fprintf(stderr, "Evaluated to %f\n", FP());
// Delete the anonymous expression module from the JIT.
ExitOnErr(RT->remove());
}
} else {
// Skip token for error recovery.
getNextToken();
}
}addModule 方法实现,该方法会为
module 中的所有函数生成代码,并将 module
与一个资源追踪器进行绑定,以用于后续从 JIT 中移除 module。当 module
注册完成后,将无法对其进行修改,因此我们需要创建一个新的 module
用于持有后续的代码,通过调用
InitializeModuleAndPassManager() 方法实现。
当 module
注册完毕后,我们需要获取一个指向最终生成代码的指针。为此,我们调用 JIT
的 lookup
方法,并传递顶层表达式函数的名称:__anon_expr。
接下来,我们通过该符号调用 getAddress() 来获取
__anon_expr
函数的内存地址。回想一下,我们将顶层表达式编译成一个自包含的 LLVM
函数,该函数不接受任何参数并返回计算的双精度值。由于 LLVM JIT
编译器与本机平台 ABI
匹配,因此我们可以将结果指针转换为该类型的函数指针并直接调用它。这意味着,JIT
编译代码和静态链接到应用程序的本机机器代码之间没有区别。
最后,由于我们不支持重新评估顶层表达式,所以当我们完成释放相关内存时,我们会从
JIT 中删除 module。然而,我们之前创建的 module(通过
InitializeModuleAndPassManager)仍然打开并等待添加新代码。
如下所示,为我们对 JIT
的测试代码。顶层表达式使用无参函数进行表示,返回了一个 double 类型的值。
1
2ready> 4+5;
Evaluated to 9.000000
下面,我们再来测试 JIT 下的函数的定义与调用,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15ready> def testfunc(x y) x + y*2;
Read function definition:
define double @testfunc(double %x, double %y) {
entry:
%multmp = fmul double %y, 2.000000e+00
%addtmp = fadd double %x, %multmp
ret double %addtmp
}
ready> testfunc(4, 10);
Evaluated to 24.000000
ready> testfunc(5, 10);
ready> Error: Unknown function referenced
上述代码中,在第二次调用 testfunc 函数时,LLVM
提示找不到 testfunc 函数,这是怎么回事?从前面介绍 JIT 的
API 中我们可以知道,module 是 JIT 的分配单元,testfunc
的定义与 testfunc 的调用(匿名表达式)处于同一个 moudle
中,当我们从 JIT 中删除 module 以释放匿名表达式时的内存时,module 中
testfunc 的定义也被删除了。因此,当我们再次尝试调用
testfunc 时,JIT 提示找不到该函数。
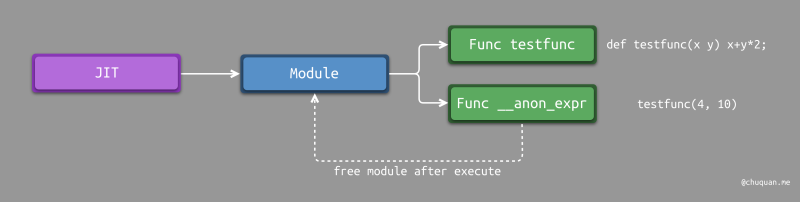
一种简单的解决方法是:将匿名表达式与函数定义放在不同的 module 中。每个函数原型都会提前注册至 JIT 中,当执行函数调用时,JIT 会进行跨 module 查找。通过将匿名表达式放在不同的 module 中,我们可以在不影响其他功能的情况下将其释放。如下所示,为该解决方法的示意图。

事实上,我们可以进一步进行优化,将每个函数定义存储在其对应的 module
中。这样的话,我们可以实现更加真实的 REPL 环境:同名函数可以多次添加至
JIT 中。当通过 KaleidoscopeJIT
查找符号时,它将返回最新的函数定义,最终达到如下所示的效果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20ready> def foo(x) x + 1;
Read function definition:
define double @foo(double %x) {
entry:
%addtmp = fadd double %x, 1.000000e+00
ret double %addtmp
}
ready> foo(2);
Evaluated to 3.000000
ready> def foo(x) x + 2;
define double @foo(double %x) {
entry:
%addtmp = fadd double %x, 2.000000e+00
ret double %addtmp
}
ready> foo(2);
Evaluated to 4.000000
为了让每个函数定义能够存储在其对应的 module 中,我们需要一种方法来重新生成函数声明,并将它们存储至新的 module 中。具体实现,如下所示:
1 | static std::unique_ptr<KaleidoscopeJIT> TheJIT; |
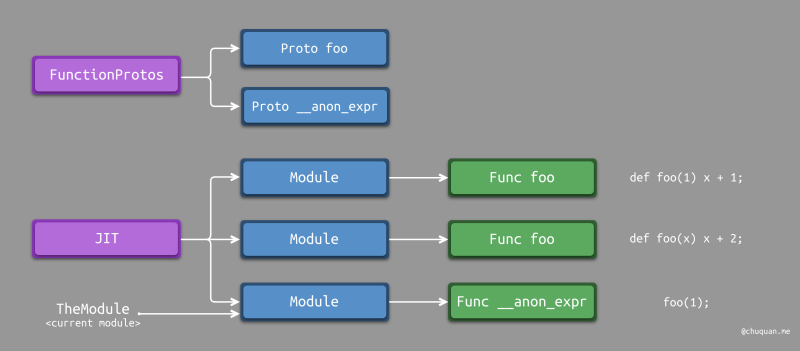
如下所示,为调整后的设计原理示意图。由于每个函数定义都对应一个模块,而
TheModule 仅仅指向当前模块。因此,无法通过
TheModule
查找其他模块中是否存在特定的函数定义。为了解决这个问题,引入了
FunctionProtos
来存储所有模块定义的函数原型,方便进行查找。
我们首先设置一个全局的
FunctionProtos,用于存储每个函数的原型,支持覆盖。此外,我们还定义一个便利方法
getFunction() 用于替换
TheModule->getFunction() getFunction()
的核心逻辑如下所示。
- 首先,在
TheModule中查找函数声明。 - 如果存在,则返回。
- 如果不存在,则在
FunctionProtos中继续查找函数声明。
在 CallExprAST::codegen() 中,我们只需要将
TheModule->getFunction() 替换成
getFunction() 即可。
在 FunctionAST::codegen() 中,我们首先更新
FunctionProtos,然后调用 getFunction()
即可。
之后,我们就可以在当前 module 中查找并调用之前声明的函数。
为此,我们还需要进行如下改造。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28static void HandleDefinition() {
if (auto FnAST = ParseDefinition()) {
if (auto *FnIR = FnAST->codegen()) {
fprintf(stderr, "Read function definition:");
FnIR->print(errs());
fprintf(stderr, "\n");
ExitOnErr(TheJIT->addModule(ThreadSafeModule(std::move(TheModule), std::move(TheContext))));
InitializeModuleAndPassManager();
}
} else {
// Skip token for error recovery.
getNextToken();
}
}
static void HandleExtern() {
if (auto ProtoAST = ParseExtern()) {
if (auto *FnIR = ProtoAST->codegen()) {
fprintf(stderr, "Read extern: ");
FnIR->print(errs());
fprintf(stderr, "\n");
FunctionProtos[ProtoAST->getName()] = std::move(ProtoAST);
}
} else {
// Skip token for error recovery.
getNextToken();
}
}HandleDefinition
函数中,我们新增了两行代码:将定义的函数注册至 JIT
中并初始化一个新的模块与通道管理器。
在 HandleExtern
函数中,我们新增了一行代码:将函数原型添加至 FunctionProtos
中。
完成上述修改后,我们再来测试一下,如下所示。此时,函函数重复定义后,能够自动匹配最新定义的函数。注意:由于
LLVM 9.0 及以后版本不支持不同模块定义相同符号,因此 LLVM 9.0
及以后版本并不支持本文所示的覆盖函数定义的能力。
1
2
3
4
5
6
7ready> def foo(x) x + 1;
ready> foo(2);
Evaluated to 3.000000
ready> def foo(x) x + 2;
ready> foo(2);
Evaluated to 4.000000
最后,我们再来测试一下能否调用外部函数。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25ready> extern sin(x);
Read extern:
declare double @sin(double)
ready> extern cos(x);
Read extern:
declare double @cos(double)
ready> sin(1.0);
Evaluated to 0.841471
ready> def foo(x) sin(x)*sin(x) + cos(x)*cos(x);
Read function definition:
define double @foo(double %x) {
entry:
%calltmp = call double @sin(double %x)
%multmp = fmul double %calltmp, %calltmp
%calltmp2 = call double @cos(double %x)
%multmp4 = fmul double %calltmp2, %calltmp2
%addtmp = fadd double %multmp, %multmp4
ret double %addtmp
}
ready> foo(4.0);
Evaluated to 1.000000sin 和
cos。这是如何做到的?事实上,KaleidoscopeJIT
内部有一个简单的符号解析规则,用于查找所注册 module
中不存在的符号:首先搜索已添加到 JIT 的所有 module,找到函数定义。如果
JIT 中没有找到定义,那么它将到 Kaleidoscope 进程自身上调用
dlsym("sin")。由于 sin 是在 JIT
的地址空间中定义的,它将 module 中对 sin 函数的调用转换成对
libm 版本的 sin
函数的调用。在某些情况下,它会更进一步,因为 sin 和
cos 是标准的数学函数名称,当使用上面的
sin(1.0) 时,常量合并优化器能够直接返回其计算结果。
后续,我们将介绍如何调整 KaleidoscopeJIT
中的这套符号解析规则,从而启用各种功能,从安全性(限制 JIT
代码可用的符号集)到基于符号名称的动态代码生成、以及懒编译(Lazy
Compilation)。
总结
至此,我们完成了对 Kaleidoscope 的 JIT 和优化器的支持。我们可以实现一门非图灵完备的编程语言,以用户驱动的方式对齐进行优化和 JIT 编译。后续,我们将研究使用控制流结构扩展编程语言,并在此过程中解决一些 LLVM IR 相关的问题。