
基于 LLVM 自制编译器(3)——LLVM IR 代码生成
概述
在上一章中,我们介绍了如何构建抽象语法树 AST。这一章,我们进一步将抽象语法树转换成 LLVM IR。此外,我们会简单介绍 LLVM 的工作原理和使用方法。
注意:本章源码要求 LLVM 版本大于等于 3.7。
初始化设置
为了支持 LLVM IR 代码生成,我们需要实现相关的初始化设置。
首先,我们在每一个 AST 类中定义虚拟代码生成方法,如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/// ExprAST - Base class for all expression nodes.
class ExprAST {
public:
virtual ~ExprAST() = default;
virtual Value *codegen() = 0;
};
/// NumberExprAST - Expression class for numeric literals like "1.0".
class NumberExprAST : public ExprAST {
double Val;
public:
NumberExprAST(double Val) : Val(Val) {}
Value *codegen() override;
};
...codegen() 方法为对应 AST
节点及其所依赖的内容生成 IR,返回一个 LLVM Value 对象。
Value 是 LLVM 中用于表示 静态单赋值(Static
Single Assignment,SSA)寄存器 或 SSA 形式
的类。静态单赋值,顾名思义,其要求每个变量只能赋值一次,并且每个变量在使用之前定义。因此,在重新计算之前,变量的值不会发生改变。
其次,我们实现了一个 LogError
方法,用于在代码生成期间报告错误,比如:未声明的参数。如下所示:
1
2
3
4Value *LogErrorV(const char *Str) {
LogError(Str);
return nullptr;
}
此外,我们定义了一系列全局静态变量,用于辅助代码生成,如下所示。
1
2
3
4static std::unique_ptr<LLVMContext> TheContext;
static std::unique_ptr<IRBuilder<>> Builder;
static std::unique_ptr<Module> TheModule;
static std::map<std::string, Value *> NamedValues;TheContenxt 是一个不透明的对象,它包含许多
LLVM
核心数据结构,比如类型和常量值表。我们不需要详细了解它,只需要一个单例来传递其所需的
API。
Builder 对象是一个辅助对象,用于生成 LLVM
指令。IRBuilder
类模板的实例能够追踪插入指令的当前位置,并能够创建新指令。
TheModule 是一个包含一系列函数和全局变量的 LLVM
数据结构。在许多方面,它是 LLVM IR
用来包含代码的顶层结构。其持有了生成的所有 IR 的内存,这也是
codegen() 方法返回 Value* 指针,而不是
unique_ptr<Value> 的原因。
NamedValues 用于存储当前作用域内所定义的值及其 LLVM
表示形式。本质上就是代码的符号表。在 Kaleidoscope
中,唯一可以被引用的是函数参数。因此,在为函数体生成代码时,函数参数将存储在
NamedValues 中。
在介绍了代码生成的基础设置之后,下面我们开始介绍如何为每个表达式生成代码。
表达式代码生成
表达式节点的 LLVM IR 代码生成非常简单。下面,我们分别进行介绍。
数值表达式
如下所示,为数值表达式的代码生成方法定义,其创建并返回一个
ConstantFP。事实上,在 LLVM IR 中,数字常量由
ConstantFP 类表示,其内部将数值保存在 APFloat
中(APFloat 能够保存任意精度浮点常量)。注意,在 LLVM IR
中,常量都是唯一且共享的。因此,API 通常使用 foo::get(...)
的用法,而不是 new foo(..) 或
foo::Create(..)。 1
2
3Value *NumberExprAST::codegen() {
return ConstantFP::get(TheContext, APFloat(Val));
}
变量表达式
如下所示,为变量表达式的代码生成方法定义,其仅检查指定变量是否在符号表
NameValues
中(如果没有,则引用未知变量)并返回它的值。在目前的定义中,我们在
NamedValues
中仅存储函数参数。在后续文章节中,我们将在符号表中支持
循环归纳变量(Loop Induction Variable)和
局部变量(Local Variable)。 1
2
3
4
5
6
7Value *VariableExprAST::codegen() {
// Look this variable up in the function.
Value *V = NamedValues[Name];
if (!V)
LogErrorV("Unknown variable name");
return V;
}
二元表达式
如下所示,为二元表达式的代码生成方法定义,其基本思想是:分别为二元表达式的左部和右部递归生成代码,然后根据操作符的类型分别计算二元表达式的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21Value *BinaryExprAST::codegen() {
Value *L = LHS->codegen();
Value *R = RHS->codegen();
if (!L || !R)
return nullptr;
switch (Op) {
case '+':
return Builder.CreateFAdd(L, R, "addtmp");
case '-':
return Builder.CreateFSub(L, R, "subtmp");
case '*':
return Builder.CreateFMul(L, R, "multmp");
case '<':
L = Builder.CreateFCmpULT(L, R, "cmptmp");
// Convert bool 0/1 to double 0.0 or 1.0
return Builder.CreateUIToFP(L, Type::getDoubleTy(TheContext), "booltmp");
default:
return LogErrorV("invalid binary operator");
}
}
在上述代码实现中,我们通过 LLVM Builder
类的相关方法来生成代码,其内部知道在何处创建指令,我们要做的就是指定指令的类型(如:CreateFAdd),指定使用的操作数(如:L
和 R),指定生成指令的名称(如:addtmp)。
关于生成指令的名称,其实只是一个提示。比如如,上述代码中如果发出多个
addtmp 变量,LLVM
将自动为每个变量提供一个递增的、唯一的数字后缀。
指令的名称完全是可选的,它的作用仅仅是提高 LLVM IR 的可读性。
LLVM
指令有着严格规则约束,比如,加法指令的左右操作数的类型必须相同,加法的结果类型必须与操作数类型相同。由于
Kaleidoscope 中的所有值都是双精度值类型,这使得
add、sub 和 mul
的代码非常简单。
此外,LLVM 规定 fcmp 指令必须返回一个 i1
值(一个一位整数)。然而,我们定义的 Kaleidoscope 希望该值是 0.0 或
1.0(浮点数)。为了获得这些语义,我们将 fcmp 指令与
uitofp
指令结合起来。后者通可以将输入整数转换为浮点值。与此相反,如果我们使用
sitofp 指令,那么 Kaleidoscope 的 <
运算符将根据输入值返回 0.0 和 -1.0。
函数调用表达式
如下所示,为函数调用表达式的代码生成方法定义。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Value *CallExprAST::codegen() {
// Look up the name in the global module table.
Function *CalleeF = TheModule->getFunction(Callee);
if (!CalleeF)
return LogErrorV("Unknown function referenced");
// If argument mismatch error.
if (CalleeF->arg_size() != Args.size())
return LogErrorV("Incorrect # arguments passed");
std::vector<Value *> ArgsV;
for (unsigned i = 0, e = Args.size(); i != e; ++i) {
ArgsV.push_back(Args[i]->codegen());
if (!ArgsV.back())
return nullptr;
}
return Builder.CreateCall(CalleeF, ArgsV, "calltmp");
}
在上述方法实现中,在 LLVM Module 的符号表中查找对应的函数。LLVM Module 是 JIT 阶段存储函数的容器。通过为每个函数指定与用户指定的名称相同的名称,我们可以使用 LLVM 符号表为我们解析函数名称。
当发生调用函数时,我们递归地对每个入参进行代码生成,并创建一个 LLVM
函数调用指令。注意,LLVM 默认使用 C
调用规范,允许这些函数调用同时调用标准库函数,如 sin 和
cos。
函数相关代码生成
函数和原型的代码生成涉及一系列的细节处理,这也使得其代码实现不如表达式代码生成实现那么简洁优雅。下面,我们来分别介绍函数原型和函数定义的代码生成。
函数原型
函数原型的代码生成也可以应用于函数定义和外部原型。如下所示,为函数原型的代码生成方法定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14Function *PrototypeAST::codegen() {
// Make the function type: double(double,double) etc.
std::vector<Type *> Doubles(Args.size(), Type::getDoubleTy(*TheContext));
FunctionType *FT = FunctionType::get(Type::getDoubleTy(*TheContext), Doubles, false);
Function *F = Function::Create(FT, Function::ExternalLinkage, Name, TheModule.get());
// Set names for all arguments.
unsigned Idx = 0;
for (auto &Arg : F->args())
Arg.setName(Args[Idx++]);
return F;
}PrototypeAST::codegen 函数返回的类型是
Function *,而不是
Value。本质上,原型用于描述函数的外部接口,而不是表达式计算的值,因此其返回代码生成时对应的
LLVM 函数,即 Function * 类型。
FunctionType::get 函数为原型创建函数类型
FunctionType。由于 Kaleidoscope
中的所有函数参数都是双精度类型,因此在调用
FunctionType::get 之前,我们根据参数的数量
Args.siz() 创建了一个包含 N 个 LLVM
双精度类型的向量。然后,使用 FunctionType::get
方法创建一个函数类型,该函数类型接受 N
个双精度类型的值作为参数,返回一个双精度类型的值作为结果。
Function::Create 函数使用函数类型创建 IR
函数,其指定函数类型、链接和名称,以及写入的目标模块。外部链接(External
Linkage)
表示该函数可以在当前模块外部进行定义,或者可以被模块外部的函数所调用。传入的
Name 参数表示用户指定的名称,由于指定了
TheModule,因此该名称会被注册在 TheModule
的符号表中。
最后,我们为每个函数参数设置名称。这个步骤并非必要,但保持名称一致会使 IR 更具有更好的可读性,并且允许后续代码直接引用参数名称,而不必在原型的 AST 中进行查找。
函数定义
如下所示,为函数定义的代码生成方法定义。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33Function *FunctionAST::codegen() {
// First, check for an existing function from a previous 'extern' declaration.
Function *TheFunction = TheModule->getFunction(Proto->getName());
if (!TheFunction)
TheFunction = Proto->codegen();
if (!TheFunction)
return nullptr;
// Create a new basic block to start insertion into.
BasicBlock *BB = BasicBlock::Create(*TheContext, "entry", TheFunction);
Builder->SetInsertPoint(BB);
// Record the function arguments in the NamedValues map.
NamedValues.clear();
for (auto &Arg : TheFunction->args())
NamedValues[std::string(Arg.getName())] = &Arg;
if (Value *RetVal = Body->codegen()) {
// Finish off the function.
Builder->CreateRet(RetVal);
// Validate the generated code, checking for consistency.
verifyFunction(*TheFunction);
return TheFunction;
}
// Error reading body, remove function.
TheFunction->eraseFromParent();
return nullptr;
}
对于函数定义,我们首先在模块的符号表中查找该函数的已有版本。如果
Module::getFunction 返回 null
则表示不存在,因此我们将通过 Proto->codegen 来生成。
然后,我们对 Builder 进行设置,具体分为两个步骤:
- 通过
BasicBlock::Create函数创建一个 基本块(Basic Block),基本块随后被插入到TheFunction中。 - 通过
Builder->SetInsertPoint函数设置基本块的末尾为指令的插入位置。LLVM 中的基本块是定义 控制流图(Control Flow Graph)中的函数的重要组成部分。 由于我们没有任何控制流语句,我们的函数此时只包含一个基本块。
随后,我们将函数参数添加到 NamedValues 符号表中,以便
VariableExprAST 节点进行访问。
当设置了代码插入点并注册了 NamedValues
符号表后,我们开始对函数体执行 codegen()
方法。如果没有发生错误,我们会进而创建一个 LLVM ret
指令,表示函数的终止。当函数构建完成后,我们调用 LLVM 的
verifyFunction
函数对生成的代码进行各种一致性检查,以确保我们的编译器是否一切正常。verifyFunction
函数非常重要,它能够检测出很多
bug。检测完毕且无错误,我们返回构造的函数。
最后的实现逻辑是错误处理。当错误发生时,我们仅通过调用
eraseFromParent
函数来删除过程中生成的函数。这样能够允许用户重新定义他们之前输入的错误函数,如果我们不删除它,它将存在于符号表中,并且无法重新定义。
驱动器适配
为了进行测试,我们对驱动器了进行简单的适配,将对 codegen
的调用插入到 HandleDefinition、HandleExtern
等函数,并在其内部打印 LLVM IR。
对于顶层二元表达式,LLVM IR
的代码生成结果如下所示。我们可以看到解析器如何为将顶层表达式转换为匿名函数的,这对于我们后续支持
JIT 是非常有用的。此外,我们可以看到生成的 IR
是逐字翻译的,除了常量合并,没有作其他任何优化。在后续的文章中,我们会显式地进行优化。
1
2
3
4
5
6ready> 4+5;
Read top-level expression:
define double @__anon_expr() {
entry:
ret double 9.000000e+00
}
对于简单的函数定义,如下所示,分别是 LLVM IR
的代码生成结果,以及生成过程的示意图。 1
2
3
4
5
6
7
8
9
10
11
12ready> def foo(a b) a*a + 2*a*b + b*b;
Read function definition:
define double @foo(double %a, double %b) {
entry:
%multmp = fmul double %a, %a
%multmp1 = fmul double 2.000000e+00, %a
%multmp2 = fmul double %multmp1, %b
%addtmp = fadd double %multmp, %multmp2
%multmp3 = fmul double %b, %b
%addtmp4 = fadd double %addtmp, %multmp3
ret double %addtmp4
}
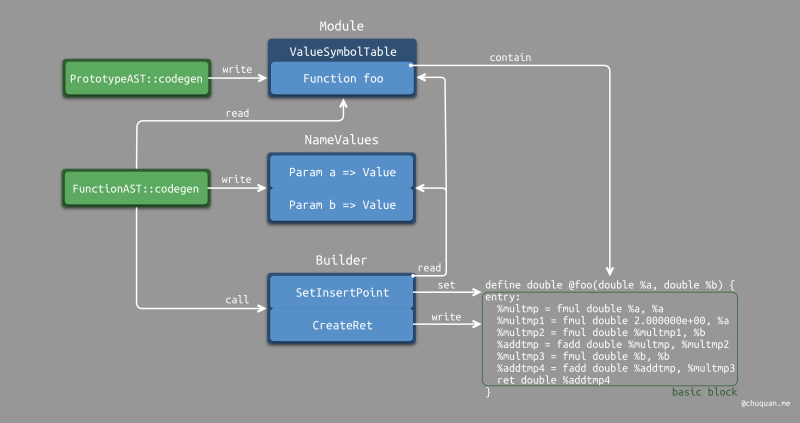
对于简单的函数调用,LLVM IR的代码生成结果如下所示。当我们调用
bar
函数时,其会消耗比较长的时间执行完毕。后续,我们添加条件控制流来优化递归。
1
2
3
4
5
6
7
8
9ready> def bar(a) foo(a, 4.0) + bar(31337);
Read function definition:
define double @bar(double %a) {
entry:
%calltmp = call double @foo(double %a, double 4.000000e+00)
%calltmp1 = call double @bar(double 3.133700e+04)
%addtmp = fadd double %calltmp, %calltmp1
ret double %addtmp
}
如下所示,为声明外部 cos 函数以及调用 cos
函数的 IR 代码。 1
2
3
4
5
6
7
8
9
10
11ready> extern cos(x);
Read extern:
declare double @cos(double)
ready> cos(1.234);
Read top-level expression:
define double @__anon_expr() {
entry:
%calltmp = call double @cos(double 1.234000e+00)
ret double %calltmp
}
当我们退出测试进程时(MacOS 系统,输入
cmd+D),其会打印生成的 Module 的所有 IR
代码。我们可以看到很多方法相互引用,如下所示: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24ready> ^D
; ModuleID = 'my cool jit'
source_filename = "my cool jit"
define double @foo(double %a, double %b) {
entry:
%multmp = fmul double %a, %a
%multmp1 = fmul double 2.000000e+00, %a
%multmp2 = fmul double %multmp1, %b
%addtmp = fadd double %multmp, %multmp2
%multmp3 = fmul double %b, %b
%addtmp4 = fadd double %addtmp, %multmp3
ret double %addtmp4
}
define double @bar(double %a) {
entry:
%calltmp = call double @foo(double %a, double 4.000000e+00)
%calltmp1 = call double @bar(double 3.133700e+04)
%addtmp = fadd double %calltmp, %calltmp1
ret double %addtmp
}
declare double @cos(double)
总结
本文,我们为解析器支持了 LLVM IR 代码生成功能,后续在此基础上,为 Kaleidoscope 支持 JIT 代码生成以及优化器。