
编译原理工具系列(1)——lex
在编译过程中,词法分析器的主要作用是将代码文件的文本内容 token 化(又称扫描),token 化后再通过语法分析器进行语法分析,构造语法树,从而完成后续的一系列操作。
宏观层面,词法分析器基于一系列正则表达式识别并构造不同的 token。原理层面,正则表达式是通过确定性有穷自动机(Deterministic Finite Automator, DFA)实现内容匹配的。微观层面,token 化是基于一系列重复繁琐的操作实现的。
lex 是一款词法分析器生成器,通过输入自定义的描述文件(包括正则表达式),我们可以生成特定的词法分析器,从而可以避免手写底层重复繁琐的实现代码。
本文,我们简单介绍一下 lex 的工作原理和基本用法。
工作原理
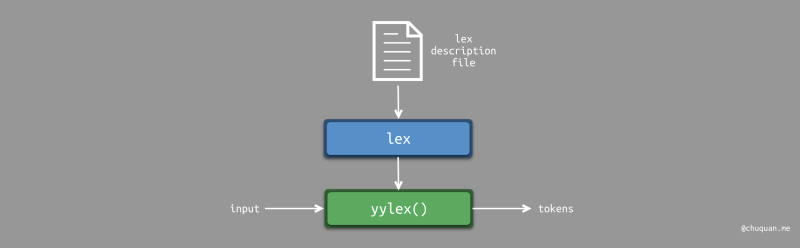
正如上文所说,lex
是一款词法分析器生成器。其输入为描述文件,输出为词法分析器。其中,词法分析器的所有逻辑由
yylex() 函数实现。
lex 的工作原理示意图如下所示:
描述文件
描述文件是 lex
生成词法分析器的核心依据,因此,我们来重点介绍一下描述文件的组成结构。描述文件的基本结构如下所示:
1
2
3
4
5
6
7
8
9<定义>
%%
<规则>
%%
<代码>
如下所示为一个 lex 描述文件的示例,文件名为 count.l。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16%{
int charcount=0,linecount=0;
%}
%%
. charcount++;
\n {linecount++; charcount++;}
%%
int main() {
yylex();
printf("There were %d characters in %d lines\n", charcount,linecount);
return 0;
}1
2
3lex -t count.l > count.c
cc -c -o count.o count.c
cc -o count count.o -ll./count,通过控制台输入文本,最后输入结束符
Ctrl+D,查看统计结果。
描述文件使用 %%
对不同的部分进行分隔,其主要包含三部分内容,分别是:
- 定义(Definitions):可选
- 规则(Rules):必选
- 代码(Codes):可选
定义
定义部分主要包含三部分内容,分别是:
- C 代码定义
- 命名正则表达式定义
- 指令定义
C 代码定义
C 代码定义基本格式如下所示: 1
2
3%{
codes
%}%{ 和
%} 之间定义 C 代码,lex
会将这些代码直接拷贝至输出文件中。一般会在这里定义变量,include
语句等。
命名正则表达式定义
命名正则表达式定义为一系列命名的正则表达式,用于描述不同的标识符,如:function、let、import,其基本格式如下所示:
1
name expression
{name}。如下所示为一个简单的示例: 1
2
3
4
5letter [a-zA-Z]
digit [0-9]
punct [,.:;!?]
nonblank [^ \t]
name {letter}({letter}│{digit})
指令定义
指令定义则是通过 lex 提供的一系列以 %
开头的指令来修改内置变量的默认值。比如:
%array:将内置的yytext变量的类型设置为char数组类型。%pointer:将内置的yytext标量的类型设置为char数组指针类型。%s STATE:定义一个STATE状态,STATE可以是任意字符串。lex 默认以INITIAL作为初始状态。%e size:定义内置的 NFA 表项的数量。默认值是 1000。%n size:定义内置的 DFA 表项的数量。默认值是 500。%p size:定义内置的 move 表项的数量。默认值是 2500。
规则
规则部分定义了一系列的 词法翻译规则(Lexical Translation Rules),每一条词法翻译规则可以分为两部分:模式 和 动作。
- 模式:用于描述词法规则的正则表达式
- 动作:模式匹配时要执行的 C 代码
词法翻译规则的基本格式如下所示: 1
2
3
4
5pattern action
// or
pattern {
action
}
匹配
当词法翻译规则的模式匹配成功时,lex 默认会将匹配的 token
值存储在 yytext 变量,将匹配的 token 长度存储在
yyleng
变量。如下所示,我们使用翻译规则来统计代码的字符数、单词数、行数。
1
2
3
4
5
6
7
8
9
10%{
int charcount=0, linecount=0, wordcount=0;
%}
letter [^ \t\n]
%%
{letter}+ {wordcount++; charcount+=yyleng;}
. charcount++;
\n {linecount++; charcount++;}
在很多场景下,词法分析器必须将识别结果返回给调用者。比如,在编译器中,当识别一个标识符时,必须同时返回
符号表表项的索引 和 token 号。由于 C
语言的 return 语句只能返回一个值,我们可以通过内置的 yylval
变量存储 token 值(即符号表项的索引)和 token 号。如下所示:
1
{name} { yyval = lookup(yytext); return(NAME); }
状态
如果词法翻译规则的模式的匹配依赖上下文,那么我们可以有不同的方式来处理。我们可以根据其所依赖上下文的相对位置,分为:左状态(Left State) 和 右状态(Right State)两种。
左状态
左状态的基本格式如下所示: 1
<STATE>(pattern) { action; BEGIN OTHERSTATE; }
STATE
为定义部分的状态定义所定义的状态,使用 %s STATE
进行定义。
右状态
右状态的基本格式如下所示: 1
pattern/context {action}
pattern 时,且紧随其后是
context,那么才算匹配成功。在这种情况下,/
后面的内容仍然位于输入流中,它们可以作为下一个匹配的输入。
代码
代码部分用于定义自定义代码,如果希望单独使用
lex,那么我们可以在代码部分里包含 main
入口函数。如果代码部分为空,那么 lex 会自动添加默认的 main
入口函数,如下所示: 1
2
3
4
5int main()
{
yylex();
return 0;
}yylex
包含了我们上述所定义的所有逻辑。
案例
假如我们希望对一段文本内容的空格进行规范化,文本如下: 1
2
3
4This text (all of it )has occasional lapses , in punctuation(sometimes pretty bad) ,( sometimes not so).
(Ha!) Is this: fun? Or what!
- 对于多个连续的空行,只能保留一个
- 对于多个连续的空格,只能保留一个
- 标点符号前,删除空格
- 标点符号后,添加空格
- 左括号后,右括号前,删除空格
- 左括号前,右括号后,添加空格
- 后括号可以紧跟标点符号
右状态方案
如下所示,为右状态方案。我们通过匹配多余的空格,并通过操作
yytext 来删除空格。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21punct [,.;:!?]
text [a-zA-Z]
%%
")"" "+/{punct} {printf(")");}
")"/{text} {printf(") ");}
{text}+" "+/")" {while (yytext[yyleng-1]==’ ’) yyleng--; ECHO;}
({punct}|{text}+)/"(" {ECHO; printf(" ");}
"("" "+/{text} {while (yytext[yyleng-1]==’ ’) yyleng--; ECHO;}
{text}+" "+/{punct} {while (yytext[yyleng-1]==’ ’) yyleng--; ECHO;}
^" "+ ;
" "+ {printf(" ");}
. {ECHO;}
\n/\n\n ;
\n {ECHO;}
%%
左状态方案
如下所示,为左状态方案。在右状态方案中,我们需要覆盖每一种情况,很容易遗漏。翻译规则的数量可能会随着我们在空格前后识别的类别数量乘积式增长。通过使用左状态方案可以避免翻译规则乘积式增长。
使用左状态,我们在 lex 内部实现了一个有限自动机,并且指定在不同的状态转移过程中如何处理空格。某些情况下,删除空格;某些情况下,掺入空格。
在左状态方案中,我们定义了 4 种状态,分别对应左括号、右括号、文本、标点符号。不同状态下,匹配相同的内容,其状态转移操作不同。
1 | punct [,.;:!?] |
总结
本文简单介绍了词法分析器生成器 lex 的基本原理,重点介绍了其描述文件的基本结构,以便后续在接触此类文件时了解其相关的结构和概念,从而能够快速上手。