
字符编码
概念
字符是一个信息单位,在计算机中,一个中文汉字是一个字符,一个英文字母是一个字符,一个阿拉伯数字是一个字符,一个标点符号也是一个字符。
字符集是字符组成的集合,通常以二维表的形式存在于每一台计算机本地,二维表的内容和大小是由使用者的语言而定的,可以是英语、汉语、希腊语等等。
字符编码是把字符集中的字符编码为特定的二进制数,以便在计算机中存储。编码方式一般是对二维表的横纵坐标进行变换的算法。一般都比较简单,直接把横纵坐标拼一起。后来随着字符集的不断扩大,为了节省存储空间,才出现了各种编码算法。
字符集和字符编码一般是成对出现的,如ASCII、IOS-8859-1、GB2312、GBK等,都是既表示了字符集又表示了对应的字符编码,下文统称编码。Unicode比较特殊,后面细说。
发展
ASCII
计算机是美国人发明的,由于他们的语言的是美式英语,字符比较少,所以一开始就设计了一个不大的二维表,128个字符,取名ASCII(American Standard Code for Information Interchange)。128个码位(包括32个不能打印出来的控制符号)只占用了一个字节的后面7位,最前面的1位统一规定为0,其表示范围为00000000-01111111或0x00-0x7F。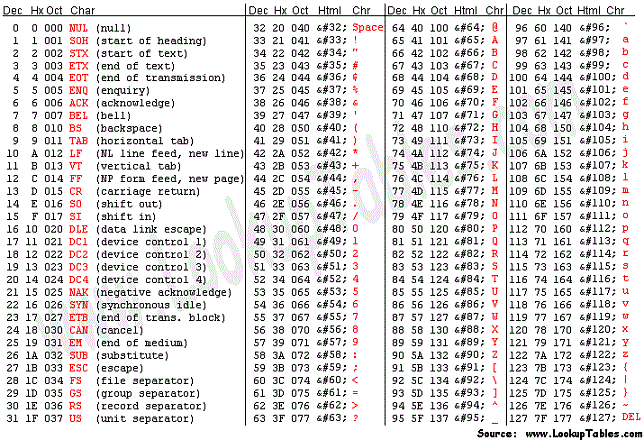
00000000-11111111或0x00-0xFF。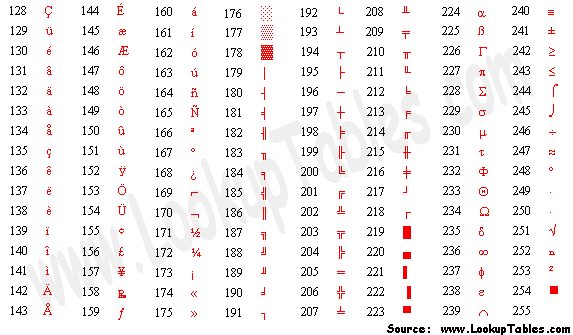
当计算机技术传递到欧洲后,美国的编码标准就不适用了,但是改改还能凑合。于是国际标准化组织在ASCII的基础上进行了扩展,形成了ISO-8859标准,跟EASCII类似,兼容ASCII,在高128个码位上有所区别。但是由于欧洲的语言环境十分复杂,所以根据各地区的语言又形成了很多子标准,如ISO-8859-1、ISO-8859-2、ISO-8859-3,......,ISO-8859-16等等。
非ASCII
单个字节表示256个字符的ASCII系编码,对于欧洲各国的语言尚可表示,然而,对于亚洲地区的语言来说则远远不够,中国的汉字就多达10万左右。因此,就必须使用多个字节表示一个字符。为此在,亚洲地区又出现了很多编码,大陆的GB2312和GBK(GB2312的扩展,Kuozhan)、港台的BIG5、日本的Shift JIS等等。例如,GB2312编码使用两个字节表示一个汉字,所以理论上最多可以表示65536个汉字。
Unicode
当互联网席卷了全球,地域限制被打破了,不同国家和地区的计算机在交换数据的过程中,一旦使用不同的字符编码就会出现乱码的问题。要彻底解决这个问题,就必须使用一个通用的字符集UCS(Universal Character Set)和一个通用的字符编码Unicode。
Unicode
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么就可以彻底解决乱码问题。这就是Unicode,就像它的名字一样,这是一种所有符号的编码。
Unicode是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字"严"。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
Unicode只是一个符号集,只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
问题
事实上,Unicode在实现上存在两个需要解决的问题: > (1)
如果采用多字节定长存储,则面临着极大的存储空间浪费以及字符集扩展问题。如:单字节的ASCII编码将浪费大量存储空间。
> (2)
如果采用多字节非定长存储,则面临着不定长编码的识别问题。即,如何知道一个编码使用了多少字节。
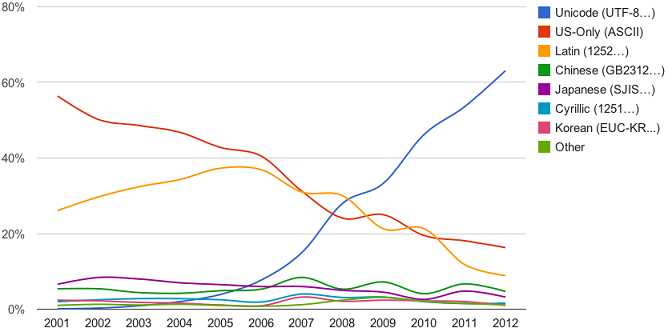
目前,有三种被广泛认知的Unicode实现方式:UTF-8,UTF-16(字符用两个字节或四个字节表示),UTF-32(字符用四个字节表示)。然而只有UTF-8有效地解决了上述两个问题,使得其成为目前最广泛的Unicode实现方式。
UTF-8
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条: > (1)
对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
> (2)
对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了UTF-8编码规则,字母x表示可用编码的位。
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|
| 0000-0000-0000-007F | 0xxxxxxx |
| 0000-0080-0000-07FF | 110xxxxx 10xxxxxx |
| 0000-0800-0000-FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001-0000-0010-FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8的编码规则:如果第一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字符。
下面,还是以汉字"严"为例,演示如何实现UTF-8编码。
已知"严"的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000
0800-0000 FFFF),因此"严"的UTF-8编码需要三个字节,即格式是"1110xxxx
10xxxxxx
10xxxxxx"。然后,从"严"的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,"严"的UTF-8编码是"11100100
10111000 10100101",转换成十六进制就是E4B8A5。
历史
- ASCII
- 1960 开发
- 1963 发布
- 1986 最后一次更新
- ISO-8859-1
- 1998 发布
- GB2312
- 1980 发布
- GBK
- 1993 发布
- UCS-2
- In the late 1980s
- Unicode
- 1987 开发
- 1991 发布
- 1996 实现代理机制(UTF-16)
- 2015 最新版8.0
- UTF-8
- 1993 发布
- 2008 流行
- UTF-16
- 1996 开发
- 2000 发布
(完)